Data Processing #
Jupter Notebook #
在cell中执行shell
!pwd #单条shell命令
%%bash #整个cell作为shell脚本
模块自动重载,否则每次修改需要重启kernel
%load_ext autoreload
%autoreload 2 #每执行一个cell都会重载所有模块
Pandas #
创建Dataframe #
# 从外部读取
read_csv()
read_excel()
# 创建空的DataFrame
Dataframe(columns=[column_name1, column_name2])
# 根据列表创建Dataframe,列表的每个元素表示一行,可以用List或Dict表示一行
Dataframe([{column1:a,column2:b},{}]) # 用字典代表一行
Dataframe([[a,b],[c,d],[e,f]],columns=['c1','c2']) # 用列表代表一行
创建新的行和列 #
# 创建新的列
df[new_column] = constant / df[a]+df[b] / df[a].apply(func) # 老版本的写法
df.loc[:,c] = df[a] + df[b] # 更建议的写法
# 创建新的行
df.loc[len(df)] = Series({column1=x,column2=y,...})
索引 #
# 索引单行单列
df[column_name]` # 索引某一列
df.loc[idx] # 索引某一行
# 索引单一元素
df.loc[idx, column_name] # 索引某个元素
df.iloc[idx, column_idx] #
# 索引多行多列
df.loc[[idx1,idx2]][[column_name1,colunmn_name2]] #索引多行多列
df.loc[[idx1,idx2],[column_name1,colunmn_name2]] #索引多行多列
# 按条件筛选
df.loc[df[a] == df[b],:] # 按列筛选的结果,本质上是一种行索引
Dataframe的统计分析
df.value_counts(column_name)
df.plot()
Matplotlib #
常用工作流
import matplotlib.pyplot as plt
plt.pca() #清空画布
plt.plot() #画折线
plt.show() #显示图片(ssh时不可用)
plt.savefig(save_path) #保存图片
柱状图/散点图
plt.bar(bins1,height=hist1) # 柱状图
plt.scatter(x,y,size,color) # 散点图
显示中文字体
from matplotlib.font_manager import FontProperties
font = FontProperties(fname="../PingFang.ttc", size=10) #配置本地字体
plt.title(title, fontproperties=font) #标题
names = "\n".join(string)
plt.xticks(range(len(names)), names, fontproperties=font, rotation=90) #横轴
Machine Learning #
PyG: pytorch_gemotry #
官方文档 #
Installation #
- 根据cuda版本和pytorch版本,选择合适的PyG版本
- 用whl安装各个PyG依赖包,然后把sparse-conv卸掉
Debug #
- 报错信息并不一定反映真实情况
- 在CPU上调试以获取尽可能有效的报错信息
- 可能是版本问题或者是dtype不一致这种基础错误
- PyG对异构图的支持不如同构图完善
- 优先使用同构图
- 异构图需要每张图都包含所有类型的节点和边,如果没有就用torch.empty()填充
- 异构图的边类型命名不能含有数字
子图采样 #
torch_geometric.utils提供了若干用于从大图中进行子图采样的API
| API | |
|---|---|
| subgraph | 只包含给点节点的子图;自动滤除没有边连接的节点;返回用全局索引表达的边和边属性 |
| k_hop_subgraph | 会给k-hop节点分配新的局部索引;edge_index是由新的局部索引来表达;edge_mask是按原始边索引的相对位置来排布的,用于筛选这些边对应的特征; |
GNN设计 #
在pyg的设计理念中,边是有向的,消息传递是沿着source节点到target节点,如果是无向边,需要自己设置两条边
TorchMetrics #
预定义指标 #
函数式
import torch
import torchmetrics
preds = torch.randn(10, 5).softmax(dim=-1)
target = torch.randint(5, (10,))
acc = torchmetrics.functional.accuracy(preds, target, task="multiclass", num_classes=5)
对象式
import torch
import torchmetrics
metric = torchmetrics.classification.Accuracy(task="multiclass", num_classes=5)
n_batches = 10
for i in range(n_batches):
# simulate a classification problem
preds = torch.randn(10, 5).softmax(dim=-1)
target = torch.randint(5, (10,))
# metric on current batch
acc = metric(preds, target)
print(f"Accuracy on batch {i}: {acc}")
# metric on all batches using custom accumulation
acc = metric.compute()
print(f"Accuracy on all data: {acc}")
# Resetting internal state such that metric ready for new data
metric.reset()
自定义指标 #
在__init__中定义不同batch计算结果的聚合方式,在update中定义每个batch的前向计算,在compute中定义所有batch计算完成后的后处理。
方式一:在每个batch进行指标计算,后处理时聚合
from torchmetrics import Metric
class MyAccuracy(Metric):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.add_state("correct", default=torch.tensor(0), dist_reduce_fx="sum")
self.add_state("total", default=torch.tensor(0), dist_reduce_fx="sum")
def update(self, preds: Tensor, target: Tensor) -> None:
preds, target = self._input_format(preds, target)
if preds.shape != target.shape:
raise ValueError("preds and target must have the same shape")
self.correct += torch.sum(preds == target)
self.total += target.numel()
def compute(self) -> Tensor:
return self.correct.float() / self.total
方式二:在每个batch保存结果,最终一起计算
from torchmetrics import Metric
from torchmetrics.utilities import dim_zero_cat
class MySpearmanCorrCoef(Metric):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.add_state("preds", default=[], dist_reduce_fx="cat")
self.add_state("target", default=[], dist_reduce_fx="cat")
def update(self, preds: Tensor, target: Tensor) -> None:
self.preds.append(preds)
self.target.append(target)
def compute(self):
# parse inputs
preds = dim_zero_cat(self.preds)
target = dim_zero_cat(self.target)
# some intermediate computation...
r_preds, r_target = _rank_data(preds), _rank_dat(target)
preds_diff = r_preds - r_preds.mean(0)
target_diff = r_target - r_target.mean(0)
cov = (preds_diff * target_diff).mean(0)
preds_std = torch.sqrt((preds_diff * preds_diff).mean(0))
target_std = torch.sqrt((target_diff * target_diff).mean(0))
# finalize the computations
corrcoef = cov / (preds_std * target_std + eps)
return torch.clamp(corrcoef, -1.0, 1.0)
Tensorboard #
记录指标 #
from torch.utils.tensorboard import SummaryWriter
# 确保日志文件夹存在
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# 创建tensorboard的指标记录器
writer = SummaryWriter(log_dir=log_dir)
# 在相应的地方保存需要可视化的指标
writer.add_scalar(loss_name, loss_val, n_iter)
端口映射与浏览器访问 #
on the local PC:
ssh -L 16006:127.0.0.1:6006 -p server_port username@server_ip
on the remote server:
tensorboard --logdir log --port=6006
PyTorch #
Dataset & Dataloader
-
transform: 一般在Dataset中定义,在返回一个Index的sample时进行处理
-
batch_sampler: 从Dataset中获取一个batch的sample, 其中index的获取取决于采样算法
-
collect_function: 将样本变成Batch
- 输入:列表,长度为Batch_size,列表的每个元素是字典,代表一个样本
- 输出:字典,每个键值对是一个类型和对应的Tensor,并且已经有了Batch_size这个维度
Tensor
快速创建tensor
torch.tensor() #将其他数据类型(list,array等)转换为张量
torch.empty()
torch.zeros()
torch.ones()
torch.rand() # 均匀分布, 0-1之间
torch.randn() # 正态分布
torch.randint() # 需要指定上下界
- 创建tensor时,需要指定size和dtype
- 一般size=(x, y, z), dtype=torch.xx
- float=float32; double=float64; int=int32; long=int64
操作tensor
#拼接
torch.cat([tensor,...], dim=0) # 在现有的维度上堆叠
torch.stack([tensor,...], dim=0) # 创建一个新的维度,在上面堆叠
# 索引
tensor[x,y,z] # 标量索引
tensor[[x1,x2],y,z] # 列表索引
tensor[tensor1,tensor2,tensor3] # 张量索引,注意一个张量只能索引一个维度
# 扩张
tensor.expand() #沿维度扩张n倍
tensor.repeat(n1, n2) # repeat的维度必须>=原始维度,并且原始的tensor会置于最后
'''
x = randn(dim1,dim2)
x.repeat(n1,n2)返回(n1*dim1,n2*dim2)
x.repeat(n1,n2,1,1)返回(n1,n2,dim1,dim2)
'''
# 转置
tensor.permute(dim1, dim2, dim3, …)
tensor.transpose(dim1, dim2) #只能二维
#变形
tensor.view(dim1,dim2,dim3,...)
tensor.reshape(dim1,dim2,dim3,...)
#计算
tensor.norm(dim, keep_dim=True) #沿指定维度求范数
# 复制+去除梯度
tensor.clone().detatch()
- permute可以对任意高维矩阵进行转置,transpose只能在两个维度之间转换,其他维度保持不变。
- view更快,reshape分配新的内存,更慢但更通用
Model
模型遍历
model.modules() #遍历model的所有子层,类比DFS搜索,有重复。
model.children() #遍历model的所有浅层
model.parameters() #保存的是Weights和Bais参数的值
模型微调
for p in self.parameters():
p.requires_grad = False
显存占用
- 模型参数:初始化产生
- 中间结果:前向传播产生(网络中如果存在一些较长的连接,比如第10层的网络需要使用来自网络第一层的输出结果,这部分的特征图就会一直占用显存)
- 模型参数的梯度:反向传播产生
- 优化器状态:例如Adam会保存每个参数的二阶梯度
常见模块的的参数量和计算量
| Module | 参数量 |
|---|---|
| Conv2d | $C_{out} \times H_{kernel} \times W_{kernel} \times C_{in}$ |
| Linear | $C_{out} \times C_{in}$ |
| MultiHeadAttention | $N_{head} \times (C_{in} \times C_{query} + C_{in} \times C_{key} +C_{in} \times C_{value})$ |
🤗 Accelerate #
- 导入并实例化
Accelerator对象 - 去除所有的
model.to(device)和batch.to(device) - 用
accelerator.prepare将model, dataloader, optimizer并行化 - 用
accelerator.backward(loss)替代loss.backward()
+ from accelerate import Accelerator
+ accelerator = Accelerator()
- device = torch.device("cuda")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer)
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# 保存模型
if args.output_dir is not None and args.num_train_epochs > 0:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(args.output_dir, save_function=accelerator.save)
基于上述代码修改,可以在命令行使用多卡或者单卡进行模型的训练
多卡
accelerate launch --multi_gpu --gpu_ids="0,1" --num_processes=2 --num_machines=1 main.py
单卡
CUDA_VISIBLE_DEVICES=0 python main.py
🤗 transformers #
customization & finetuning of PLM
如果不需要调整模型结构,那么仅通过AutoClass即可调用PLM来实现一系列下游任务
model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=5)
如果要实现更加定制化的操作,PLM也可以作为Backbone组件,实现自定义结构的下游任务模型
AutoConfig通过from_pretrained导入PLM的超参数,并支持添加新的自定义参数
AutoTokenizer通过from_pretrained与PLM保持一致
CustomModel则需要满足:
- 继承自PLM对应的
PreTrainedModel,里面会有初始化方法,否则需要自己写权重初始化 - 在
__init__中定义PLM的结构、init_weights初始化 - 在
forward中调用PLM进行计算 - 在微调之前,
from_pretrained导入预训练权重
class CustomModel(PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.prtrained_model = ResNet(config)
self.classifier = Linear(config.hidden_size, config.num_labels)
self.init_weights()
def forward(self, tensor, labels=None):
hidden_states = self.prtrained_model(tensor)
logits = self.classifier(hidden_states)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
config = AutoConfig.from_pretrained(model_name_or_path, num_labels=num_labels)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = CustomModel.from_pretrained('pretrained_model', config)
Basic #
re #
import re
text = "Hello, my email is example@email.com"
pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
# 使用 re.findall 匹配所有符合模式的子字符串,以列表返回
matches = re.findall(pattern, text)
# 使用 re.sub 将指定模式的子串替换为新子串
redacted_text = re.sub(pattern, "REDACTED", text)
# 使用 re.split 按指定模式的子串分割文本
parts = re.split(pattern, text)
# 使用 re.search 搜索文本, 返回第一个匹配项的首尾位置
match = re.search(pattern, text)
# 使用 re.match 验证字符串是否符合模式
bool(re.match(pattern, number))
正则匹配,格式是字符+限定符
限定符
| ? | 0或1个 |
| * | 任意个 |
| + | 1个以上 |
| {m,n} | m-n个 |
字符、元字符
| [a-zA-Z0-9][abc] | 小写或大写或数字a或b或c ; 否定:[^a-z] |
| a|b|c | a或b或c |
| \w | 单词(英文/数字/下划线) |
| \d | 数字 |
| \s | 空格(包括换行等) |
| \b | 边界 e.g.\bword\b |
| . | 任意字符 |
- 正则表达式在线测试工具
- 正则表达式里有转义符""时,应该在字符串前加“r”
os #
查看和更改工作目录,以及工作目录的文件情况
os.getcwd(path) #查看工作目录
os.chdir(path) #改变工作目录
os.listdir(path) #浏览工作目录
os.mkdir(path) #创建文件夹
os.remove(path) #删除文件
shutil #
文件/文件夹的复制、删除、重命名
shutil.copy(src, dst) #复制文件
shutil.copytree(src, dst) #复制文件夹
shutil.move(src, dst) #重命名文件/文件夹
shutil.rmtree(src, dst) #删除文件夹
- os.remove()方法只能删除某个文件; os.mdir()只能删除某个空文件夹 压缩
shutil.make_archive(base_name, format='zip')
glob #
包括*、**、? 、[ ]这四个通配符。
* 匹配0个或多个字符
** 匹配所有文件、目录、子目录和子目录里的文件
? 匹配一个字符
[] 匹配指定范围内的字符,如[0-9]匹配数字,[a-z]匹配小写字母
pathlib #
操作文件路径
p.name #获取文件名
p.suffix #获取文件后缀
json #
#读取
with open(filename,'r') as f:
json_dict = json.load(f)
json_string = json.loads(f)
#写入
with open(filename,'w') as f:
json.dump(json_dict, f, ensure_ascii=False)
ipdb #
ipdb.set_trace()
代码会在执行到断点处时暂停,可通过vscode内置terminal查看各个变量的状态
Advanced Grammar #
Basic Data Class #
| Tips | |
|---|---|
| List | 查找效率非常低 |
| Dict | |
| Set | 无序,顺序是随机的 |
Function #
函数签名 #
def f(x: int, b: float):
pass
参数组合 #
定义函数时,可使用必选参数、默认参数、可变参数、关键字参数和命名关键字参数。
这5种参数都可以组合使用,但必须按顺序使用。
有多个默认参数时,调用的时候,既可以按顺序提供默认参数,也可以不按顺序提供部分默认参数。当不按顺序提供部分默认参数时,需要把参数名写上。
比如定义一个函数,包含上述若干种参数:
def f1(a, b, c=0, *args, **kw):
pass
def f2(a, b, c=0, *, d, **kw):
pass
在函数调用的时候,必须先按顺序传入,再按参数名传入。
由于Python解释器会按上述顺序解析5种参数,因此,如果要传入可变参数,必须先传入默认参数。
解包 #
对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。
tuple用*解包,dic用**解包。
args = (1, 2, 3, 4)
kw = {'d': 99, 'x': '#'}
f(*args, **kw)
-
zip()表示压缩;zip(*)表示解压>>> a = [1,2,3] >>> b = [4,5,6] >>> zip(a,b) # 返回一个对象 <zip object at 0x103abc288> >>> list(zipped) # list() 转换为列表 [(1, 4), (2, 5), (3, 6)] >>> a1, a2 = zip(*zip(a,b)) # 与 zip 相反,zip(*) 可理解为解压 >>> list(a1), list(a2) [1, 2, 3], [4, 5, 6]
装饰器 #
装饰器定义复杂,使用简单
定义装饰器log,使得装饰后的函数在每次调用时打印函数名称,其中@functools.wraps(func)可以保持装饰后函数的__name__属性不变
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
使用装饰器只需要在需要装饰的函数定义前加@log即可
@log
def my_func(*args,**kw):
pass
匿名函数和偏函数 #
lambda在传参时传的是变量;partial在传参时传的是对象;
Iterator #
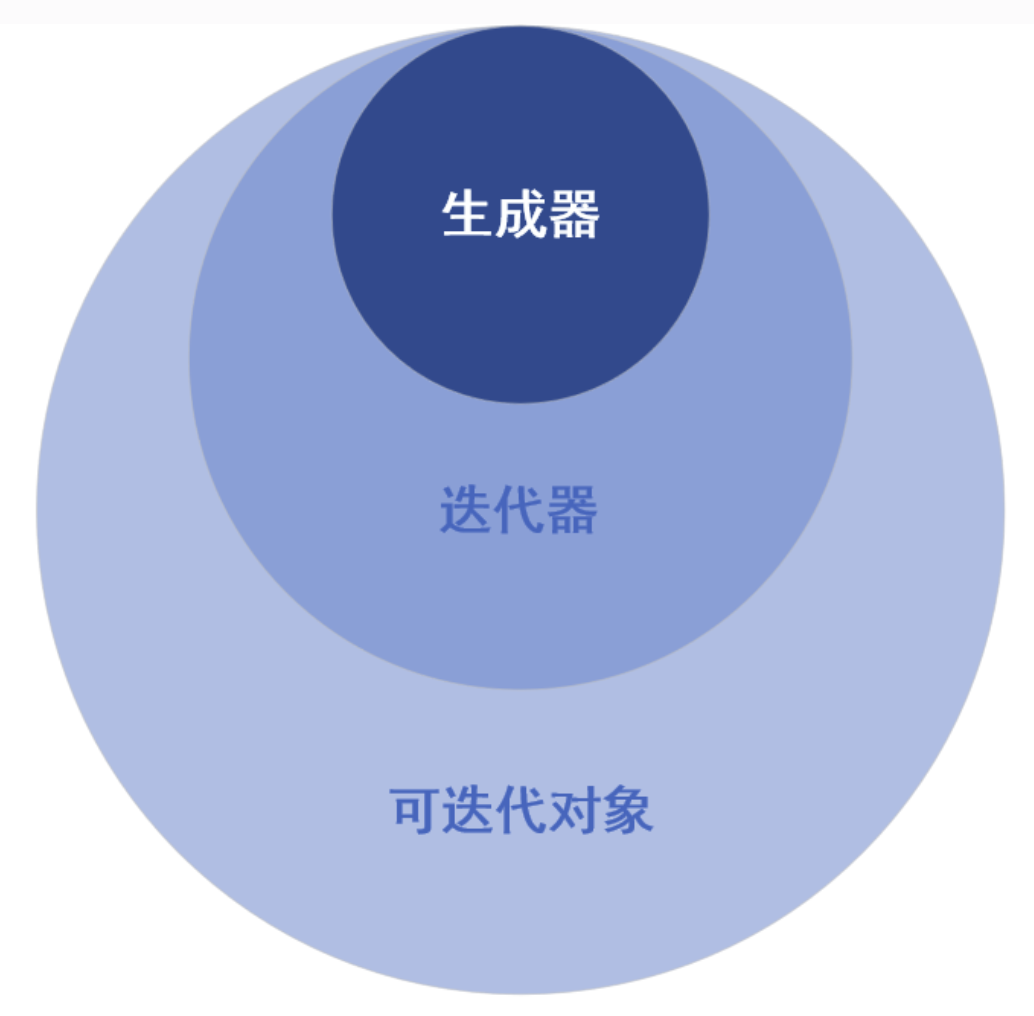
| 可迭代对象 | 定义 | 举例 | |
|---|---|---|---|
| 一般可迭代对象 | 可通过for循环遍历的对象,可通过索引访问 | 字符串、列表、字典、集合…… | |
| 迭代器 | 惰性遍历,通过next访问下一个 | 一般可迭代对象创建的迭代器(使用iter创建)、生成器(使用yield创建) |
for循环的本质是通过iter方法获取可迭代对象的迭代器
Object #
静态变量
Class A:
a: List[int]
b: Dict[float] | str
方法
- 内置方法
- 实例方法
- 实例方法最少也要包含一个 self 参数,调用时Python会自动将对象传给self参数
- 实例方法一般由对象直接调用,也支持使用类名调用实例方法,但此方式需要手动给 self 参数传值
- 类方法
- 类方法需要使用
@classmethod修饰符进行修饰 - 类方法至少要包含一个参数,通常将其命名为 cls,调用时Python 会自动将类本身传给 cls 参数
- 类方法推荐使用类名直接调用,当然也可以使用实例对象来调用(不推荐)
- 类方法需要使用
- 静态方法
- 静态方法需要使用
@staticmethod修饰 - 相当于函数,唯一的区别是静态方法定义在类命名空间中,而函数定义在程序的全局命名空间中
- 既没有类似 self、cls 这样的特殊参数,也无法调用任何类属性和类方法
- 既可以由类调用,也可以由对象调用
- 静态方法需要使用
Modules #
换镜像源
pip config set global.index-url https://pypi.mirrors.ustc.edu.cn/simple # 永久切换
安装第三方库
普通安装
pip install package #安装到python安装目录,可编辑,更新后被覆盖
pip install package -e #安装到工作目录,便于修改
pip install -i ``https://pypi.mirrors.ustc.edu.cn/simple`` matplotlib # 临时指定镜像
pip install -r requirements.txt # 批量安装
导入第三方库
-
相对导入的根目录是第一个被执行的python文件所在的位置,可通过sys查看,与os工作目录无关
-
sys.path.append() ## NOQA: E402将项目目录暂时添加到环境变量PYTHONPATH中 -
“.“导入仅限于package内部