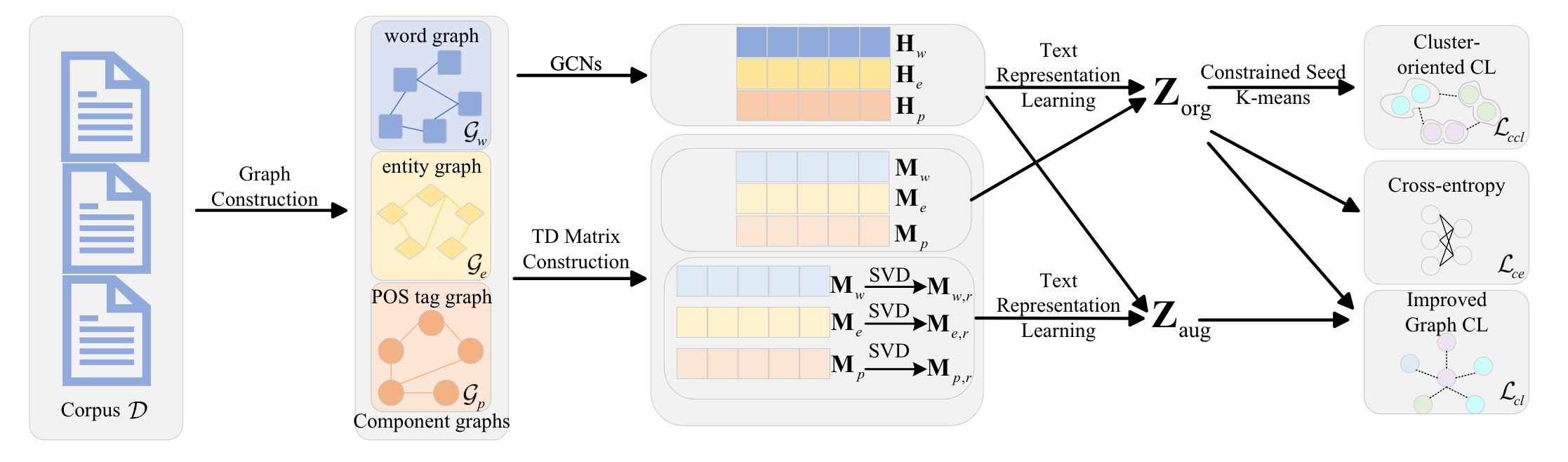
从语料库中构建3种类型的图,单词、实体、词性。
Word Graph采用GloVe word vectors作为节点嵌入,PMI作为边权重;
Entity Graph采用TransE获取节点嵌入,cosine similarity作为边权重;
Pos Graph采用One-hot作为节点嵌入,PMI作为边权重。
这些嵌入可以通过GNN来进一步聚合邻域的信息。 $$ H^{l+1}=\sigma(\hat{D^{-\frac{1}{2}}}\hat{A}\hat{D^{-\frac{1}{2}}}H^lW^l) $$ 基于这些嵌入,进一步可以构建出文本的表示,对于单词和词性,采用TF-IDF作为系数矩阵,对于实体,则只用0和1来区分文本是否存在该实体,$M_\pi$表示文本与单词、实体、词性之间的系数矩阵。 $$ Z_\pi = M_\pi H_\pi , \pi \in {w,e,p} $$
$$ Z_{org} = Z_w || Z_e || Z_p $$
$Z_{pi}$是文本的原始特征表示,可以使用SVD进行进一步的去噪和增强,获得增强的文本表示。 $$ M_{\pi , r} = U_{\pi,r}\Sigma_{\pi,r}V_{\pi,r}^T $$
$$ Z_{\pi,r}=M_{\pi,r}H_\pi $$
$$ Z_{aug}=Z_{w,r}||Z_{e,r}||Z_{p,r} $$
对于无标签的文本,采用对比学习和聚类对比学习损失。
实例对比学习将每个实例与其增强表示拉近,与其他实例及其增强表示拉远。 $$ L_{cl} = -\sum_{i=1}^{2N}\frac{1}{2N}log\frac{exp(P_i\cdot P_j / \tau)}{\sum_{k=1}^{2N}\prod_{k\neq i}exp(P_i\cdot P_k / \tau)} $$ 聚类对比学习将每个实例与其伪标签(聚类中心)相同的实例拉近,与其他实例拉远。 $$ L_{ccl} = -\sum_i^N \frac{1}{|S_i|-1}\sum_{j\in S_i}log\frac{exp(Q_i\cdot Q_j/\tau)}{\sum_{k=1}^N\prod_{k \neq i}exp(Q_i\cdot Qk/\tau)} $$ 对于有标签的文本,采用交叉熵损失。 $$ L_{ce}=-\sum_{i\in D_{lab}}\sum_j^cy_{ij}logR_{j} $$
$$ L=\eta L_{cl}+\zeta L_{ccl}+L_{ce} $$

流程如图,首先构建Graph,用GNN聚合,然后基于TD矩阵获取文本表示,使用SVD增强,最后利用这些文本表示进行对比学习和分类学习。
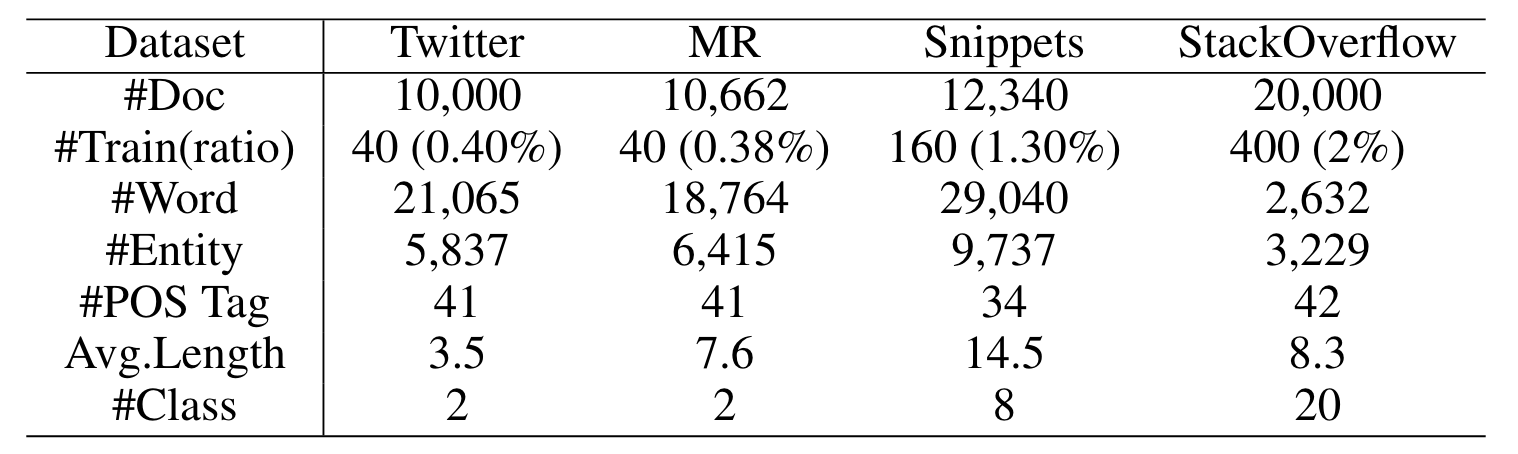
采用了4个社交媒体的短文本数据集,只使用0.4%到2%的数据,即可实现2到20分类。
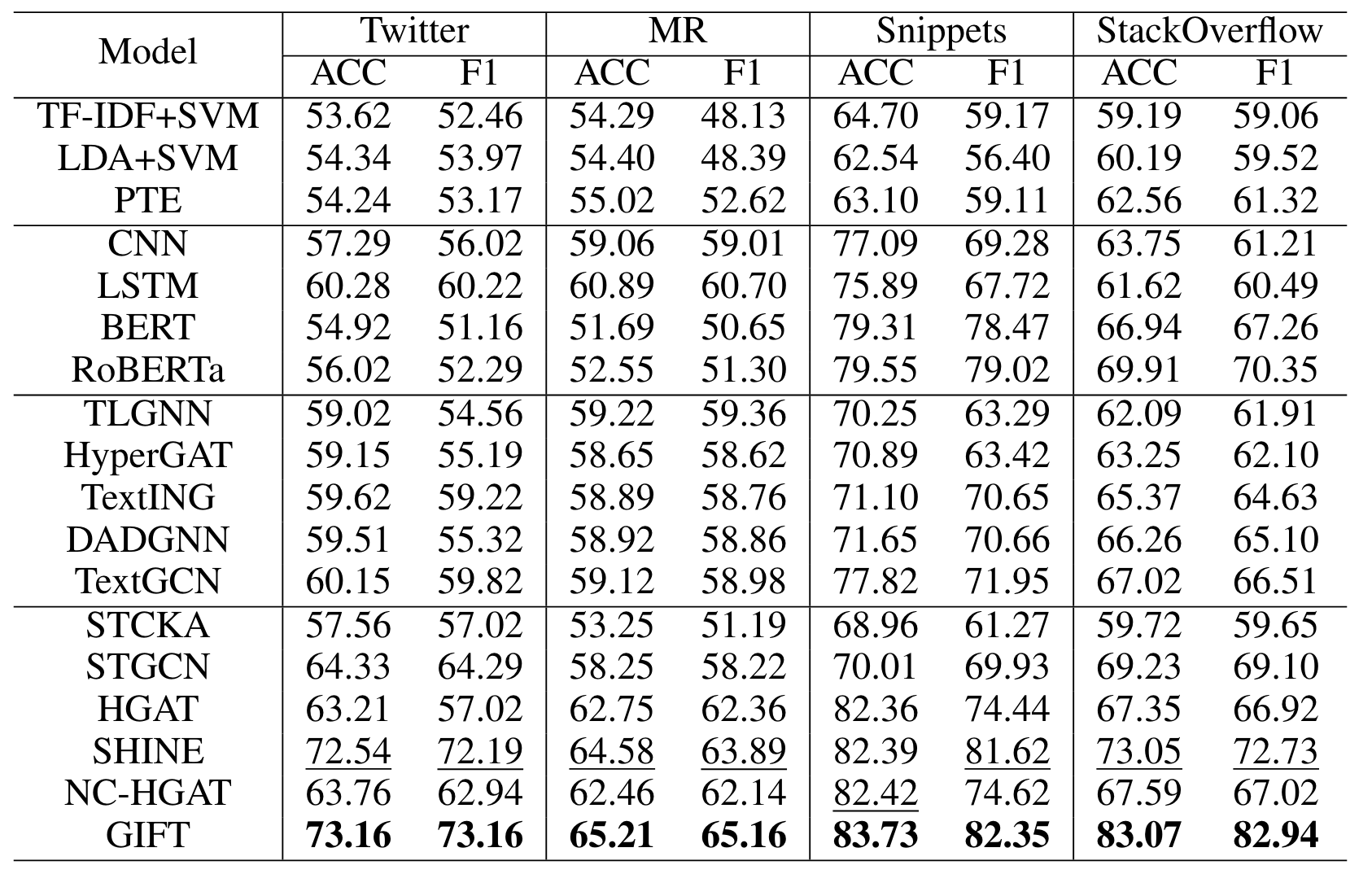
相比之前的方法有显著提升。