在MIMIC III上首次完成了topical text segmentation任务,该任务主要是基于相邻句向量之间的相似度。
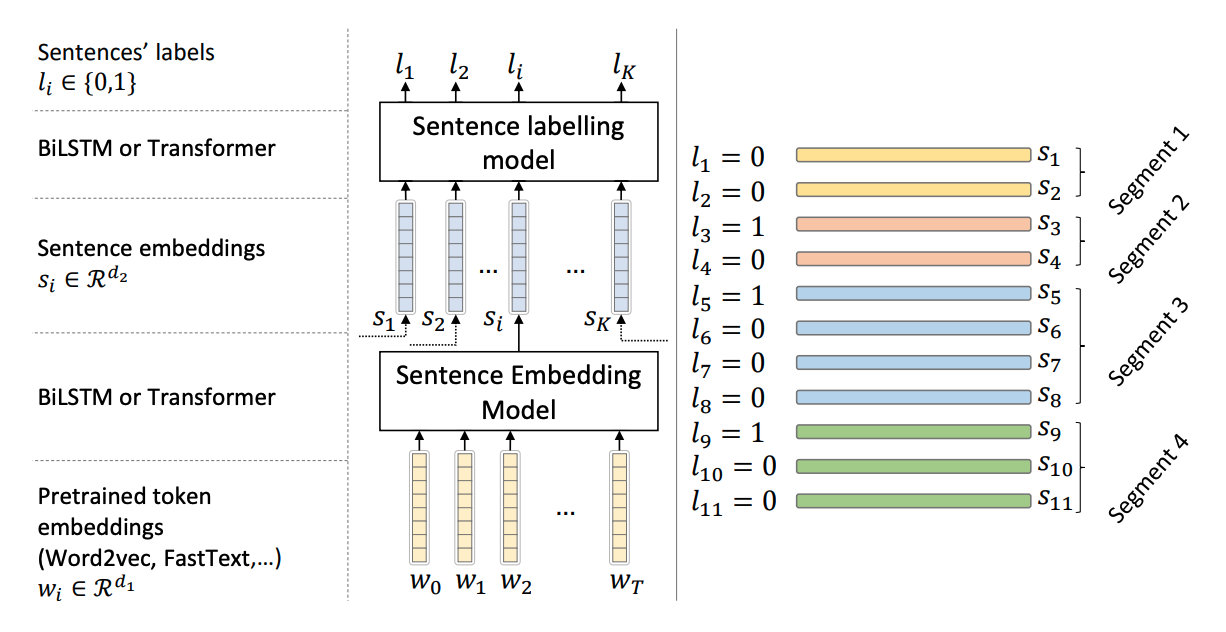
首先使用句嵌入模型将token序列压缩为句向量,然后再使用句序列模型对句子之间的语义突变关系进行建模。
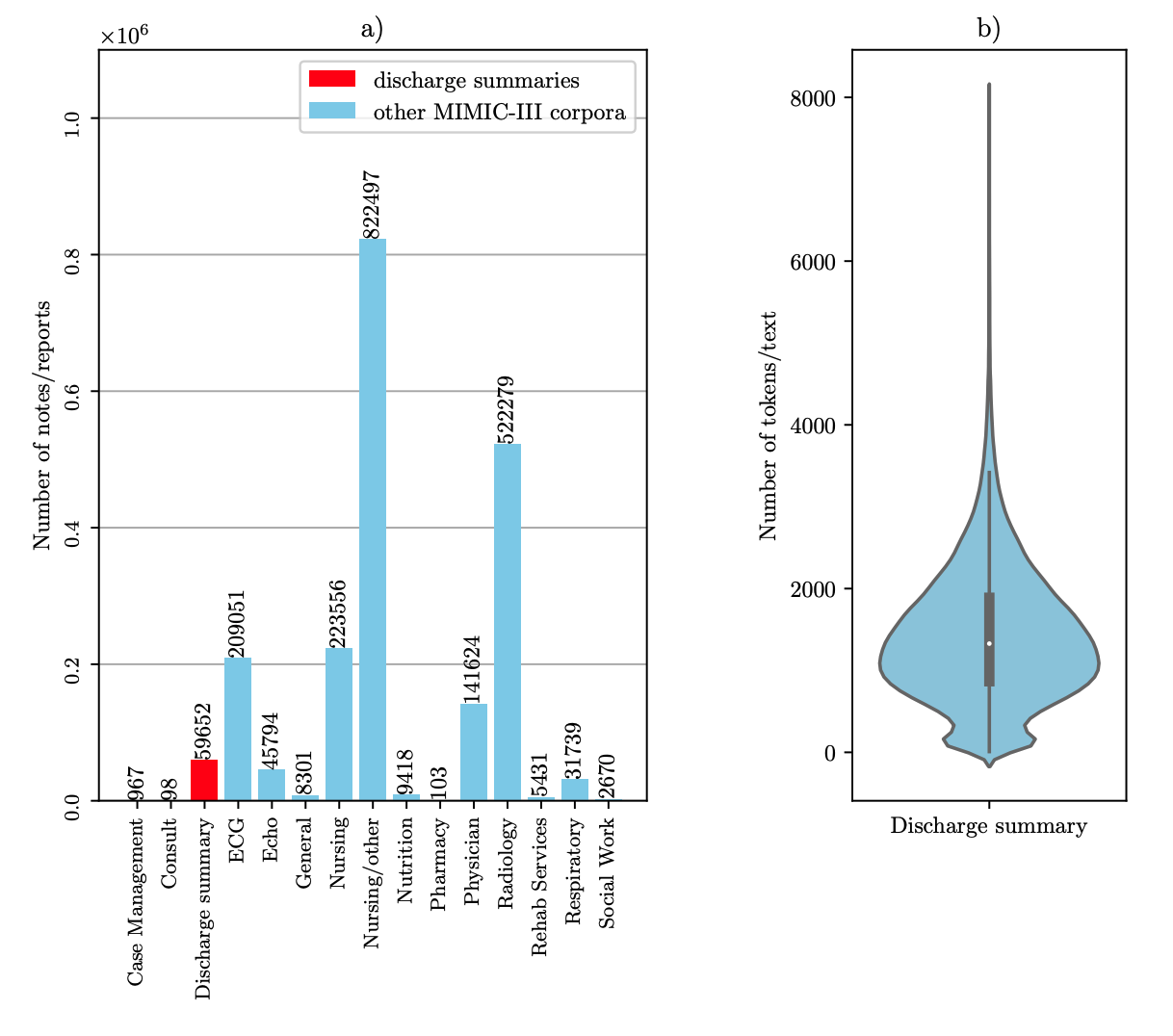
在MIMIC III数据集中,discharge summaries只占很少的一部分,约60k份报告,而它的token数集中在1500左右。
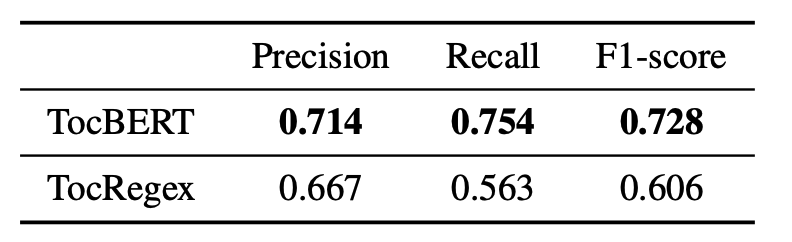
层次化文本分割:划分子标题
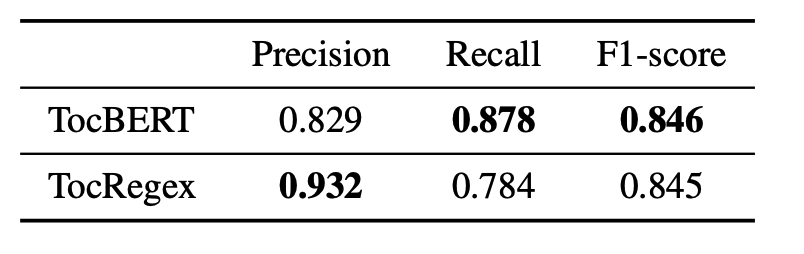
线性文本分割:不划分子标题
在各个任务上,TocBERT相比规则匹配的方法TocRegex,前者基于后者的标注作训练,却能在测试集上取得更好的效果
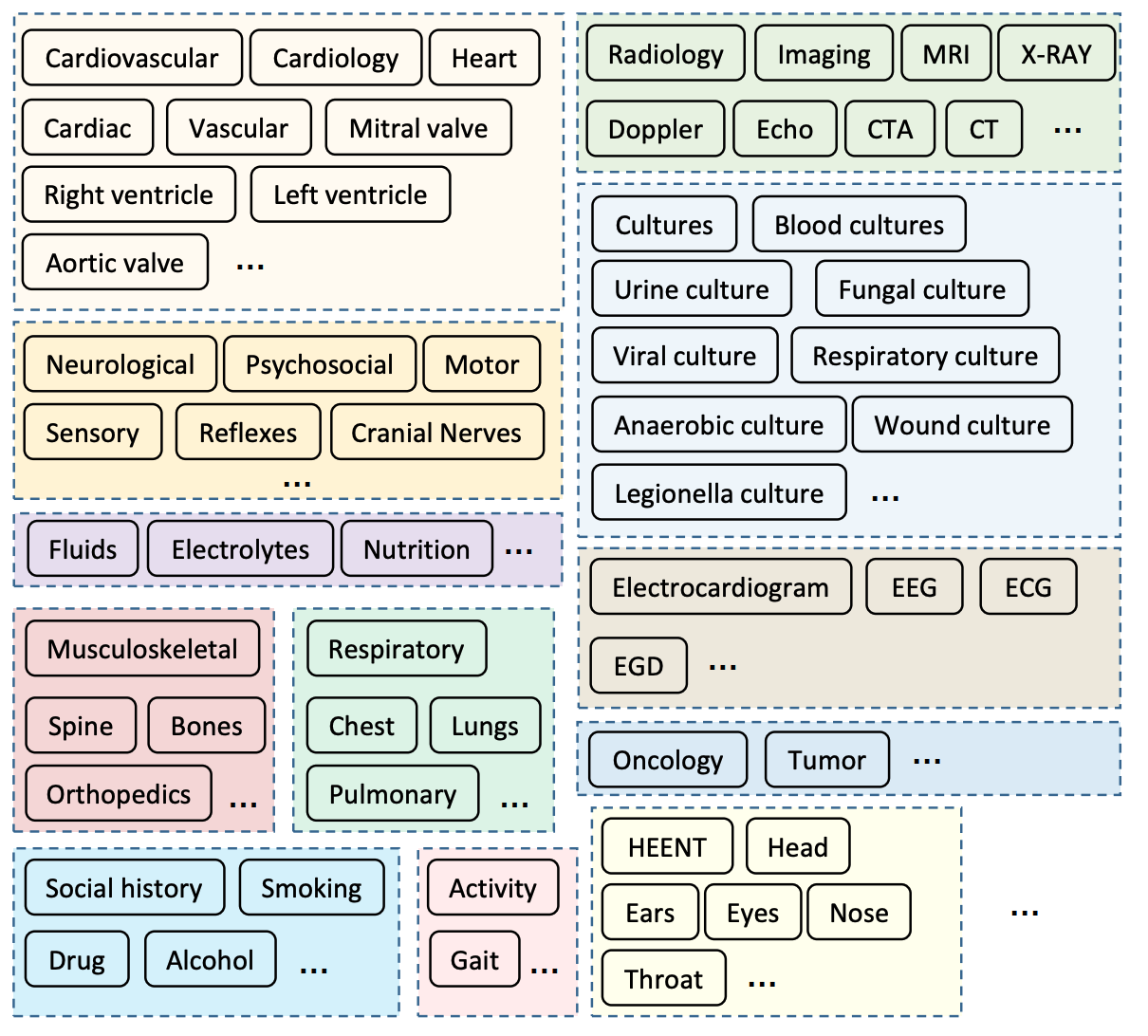
TocBERT的一个可能的作用是构建标题和子标题的本体论(KG可以看成是本体论的一个应用)