如何做VQA? #
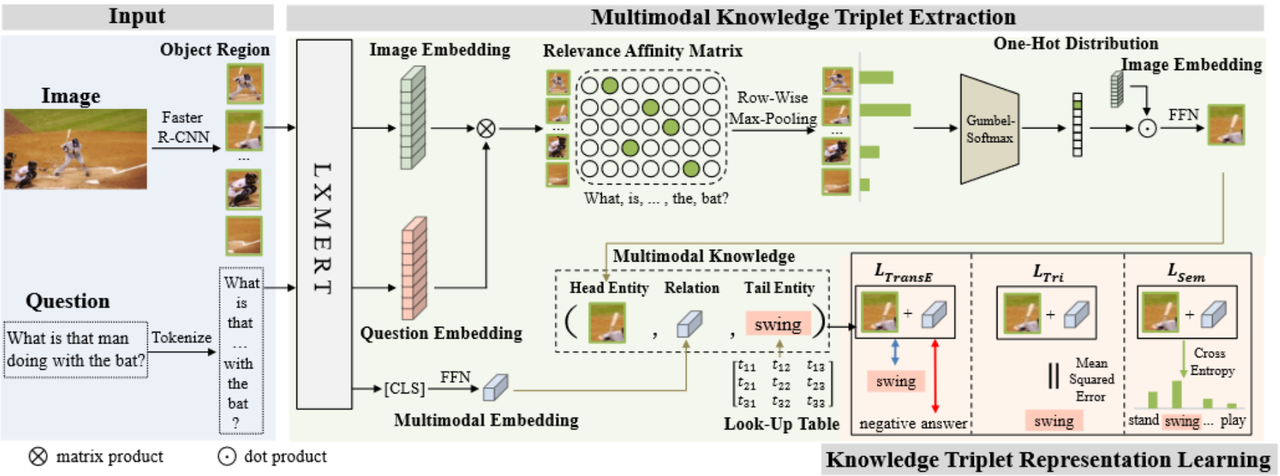
本质:图谱补全(头+关系==预测==>尾)
基于神经网络来建模头节点和关系向量
如何训练? #
基于TransE算法来实现逻辑推理关系,同时设计不同尺度的损失函数
- 靠近正确答案,远离错误答案
$$ L_{transE}=\sum_{t^+\in A^+}\sum_{t^-\in A_-}[\gamma+d(h+r,t^+)-d(h+r,t^-)] $$
- 靠近正确答案
$$ L_{Tri}=MSE(h+r,t^+) $$
-
多个答案对比
$$ P(t^+)=softmax(T^T(h+r)) $$
$$ L_{Sem}=-log(P(t^+)) $$
为什么有效? #

因为能(结合图像)正确地捕捉到头部实体和关系,同时(多模态)知识库更完备
数据集 #
OKVQA and KRVQA