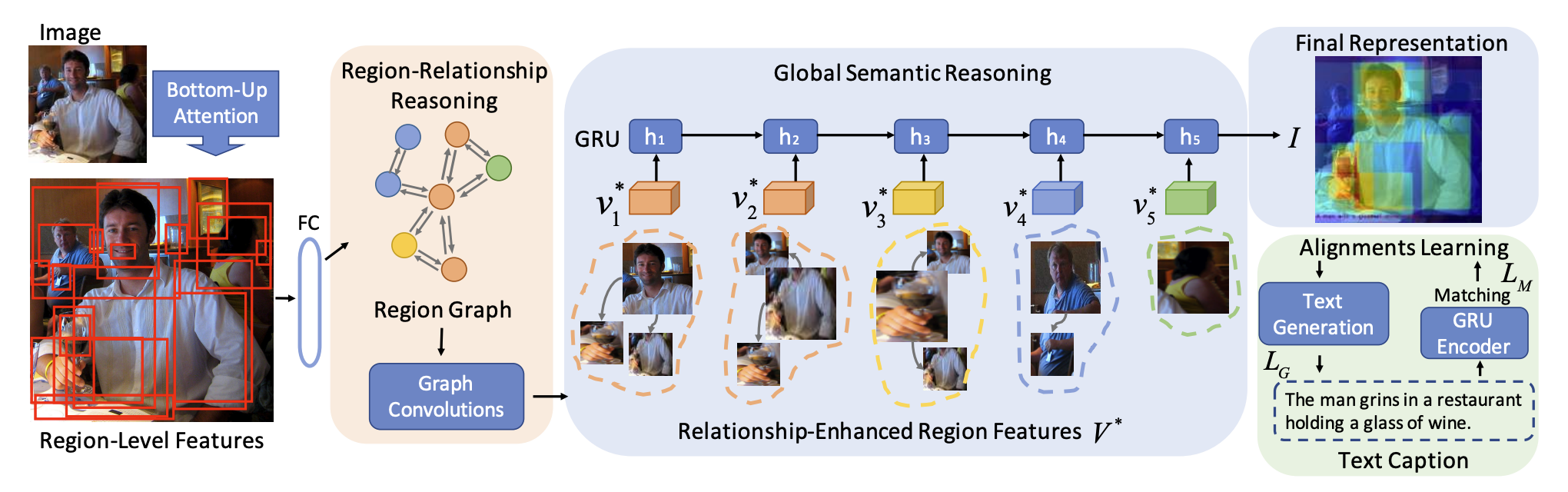
用Backbone是ResNet101的Faster-R-CNN和非极大值抑制提取若干个对象的特征,使用相似度建立边,使用GCN来使对象间产生交互,使用GRU来获取最终的全局表示。
图文之间的匹配损失是triplet loss,为正样本和负样本之间的距离设置间隔参数,并将mini batch中的难样本作为负样本。 $$ L_M=[\alpha-S(I,C)+S(I,\hat{C})]+[\alpha-S(I,C)+S(\hat{I},C)] $$ 图生文的损失是对数似然损失。
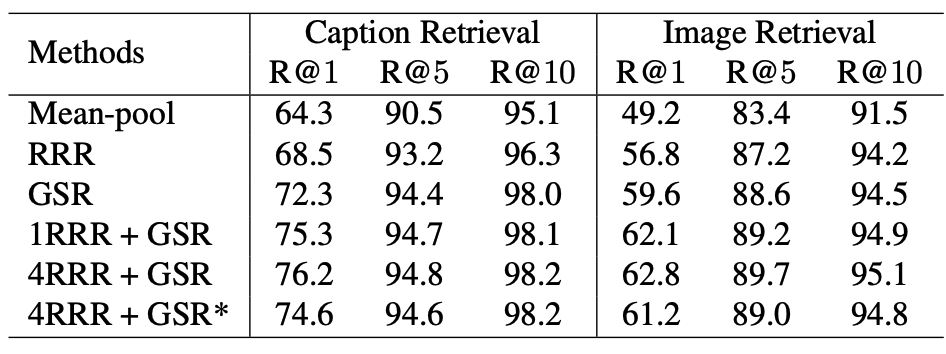
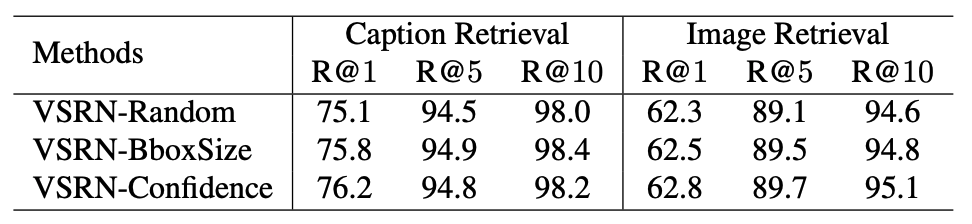
用Backbone是ResNet101的Faster-R-CNN和非极大值抑制提取若干个对象的特征,使用相似度建立边,使用GCN来使对象间产生交互,使用GRU来获取最终的全局表示。
图文之间的匹配损失是triplet loss,为正样本和负样本之间的距离设置间隔参数,并将mini batch中的难样本作为负样本。 $$ L_M=[\alpha-S(I,C)+S(I,\hat{C})]+[\alpha-S(I,C)+S(\hat{I},C)] $$ 图生文的损失是对数似然损失。