用相似报告和KG来查询潜在的实体,以用于报告解码时的文字表达。
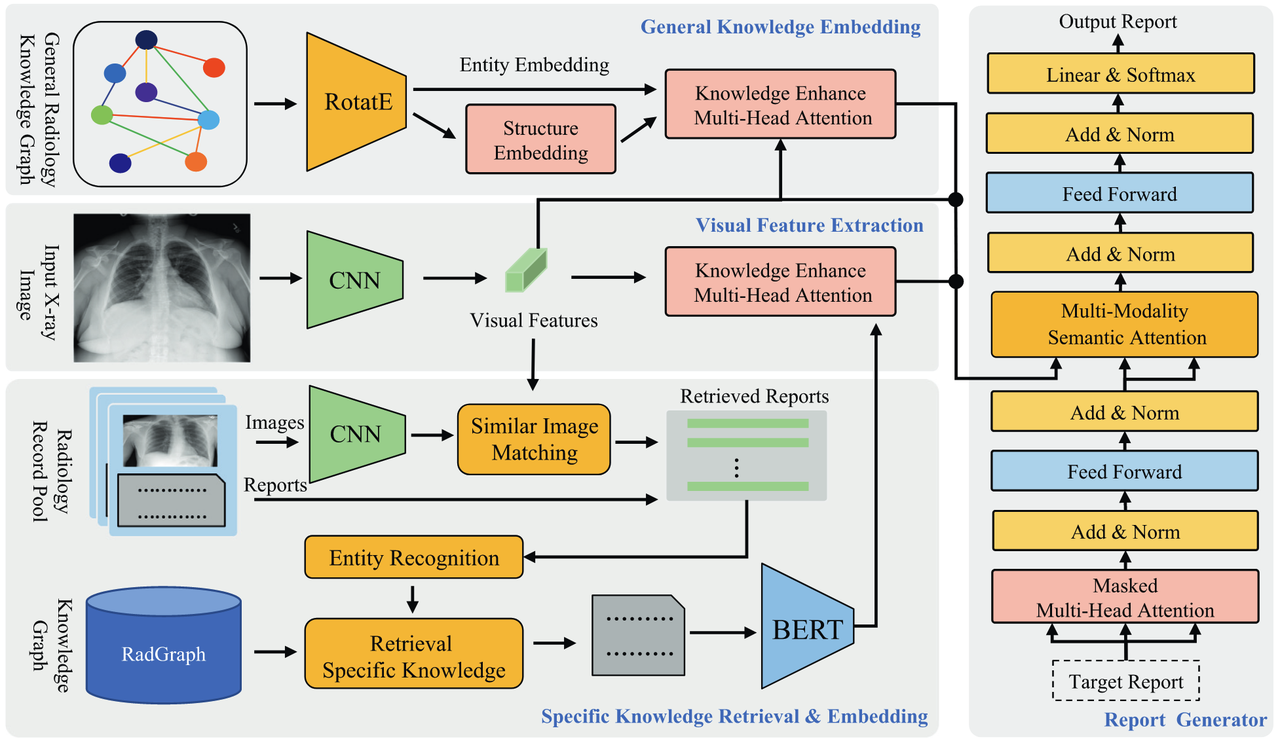
General Knowledge #
构建知识图谱 #
RadGraph Training Dataset (triplets extracted by experts from 500 MIMIC-CXR reports)
图算法编码,得到entity和relation的embedding #
$$ E_e,E_r=RotatE(G_g) $$
计算每个entity的相对重要性 #
$$ r_{i,j}=AvgPool(E_r^{(i,j)}) $$
$$ E_r^{(i,j)}=Ralation(e_i,e_j) $$
$$ \phi(r)=AvgPool(rW^R) $$
考虑相对重要性的多头注意力 #
$$ KG-Att(Q,K,V,\phi(r))=softmax(\frac{QK^T}{\sqrt{d_k}}+\phi(r))V $$
$$ C_g=KEMHA(I,E_e,E,e,r) $$
Specific Knowledge #
相似报告检索 #
使用预训练的疾病14分类模型,计算输入图像的疾病分布和库中样本的疾病分布的KL散度,选取Top K相似报告
特定知识查询 #
使用命名实体识别器Stanza提取报告中的entity,在Rad Graph Inference Dataset中查询每个entity对应的triplet
例:检索到的报告为““pneumothorax or pleural effusion is seen”,提取的实体集合T为{pneumothorax, pleural, effusion},检索到的知识为 {pneumothorax suggestive of bleeding, effusion located at bilateral,…}
知识编码 #
将一张图查询到的所有Triplets连成一句话,使用Clinical-Bert进行编码 $$ E_s=BERT(k) $$
$$ C_s=KEMHA(I,E_s,E_s,0) $$
自回归解码得到报告 #
- $$ w_t=Decoder(concat(I,C_g,C_s),w_{<t}),w_0=0损失函数 $$
$$ L=\sum_t^T{logp_\theta(w_t|w{<t},Img,g_s,g_g)} $$