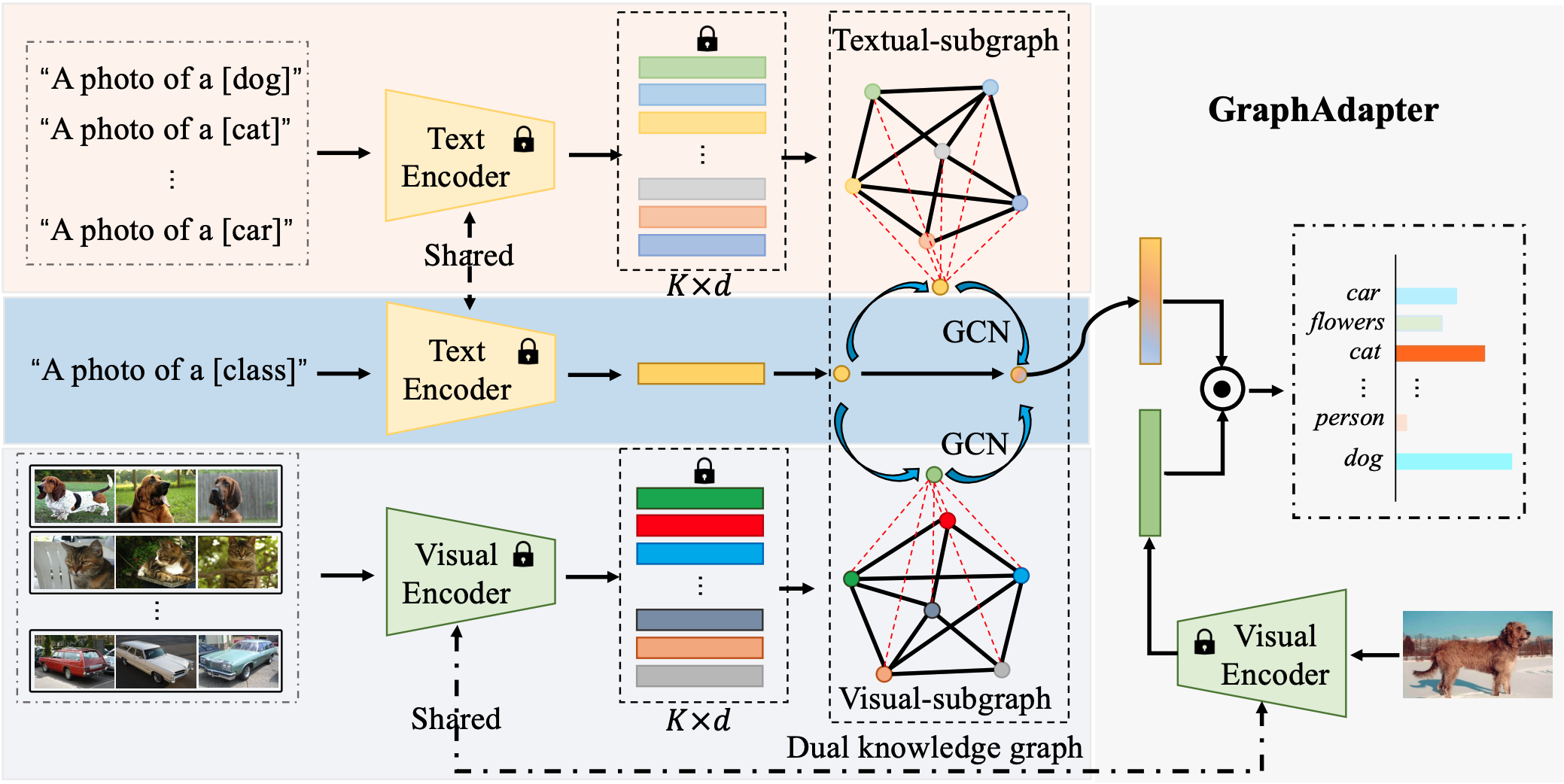
当预训练VLM迁移到新数据集时,首先对这个数据集中所有类别的文本和图像建立子图,然后基于这些子图来训练GCN进行进一步的微调,使VLM能适应新数据集上的新类别和新任务。
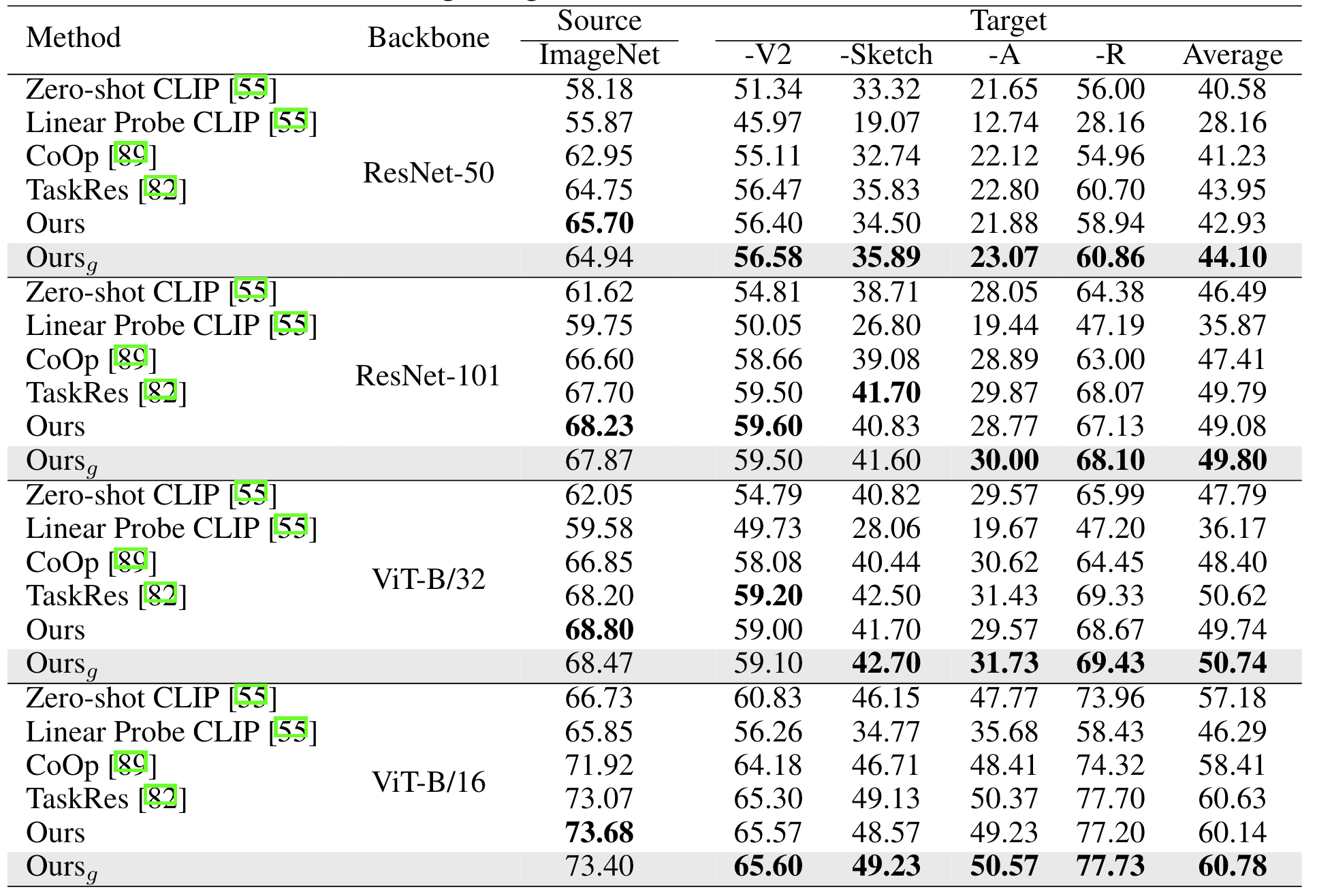
通过调节模型在新数据集上的残差系数,模型可以更好的拟合新数据集,与此同时,在其他数据集上的泛化性会变得更差。
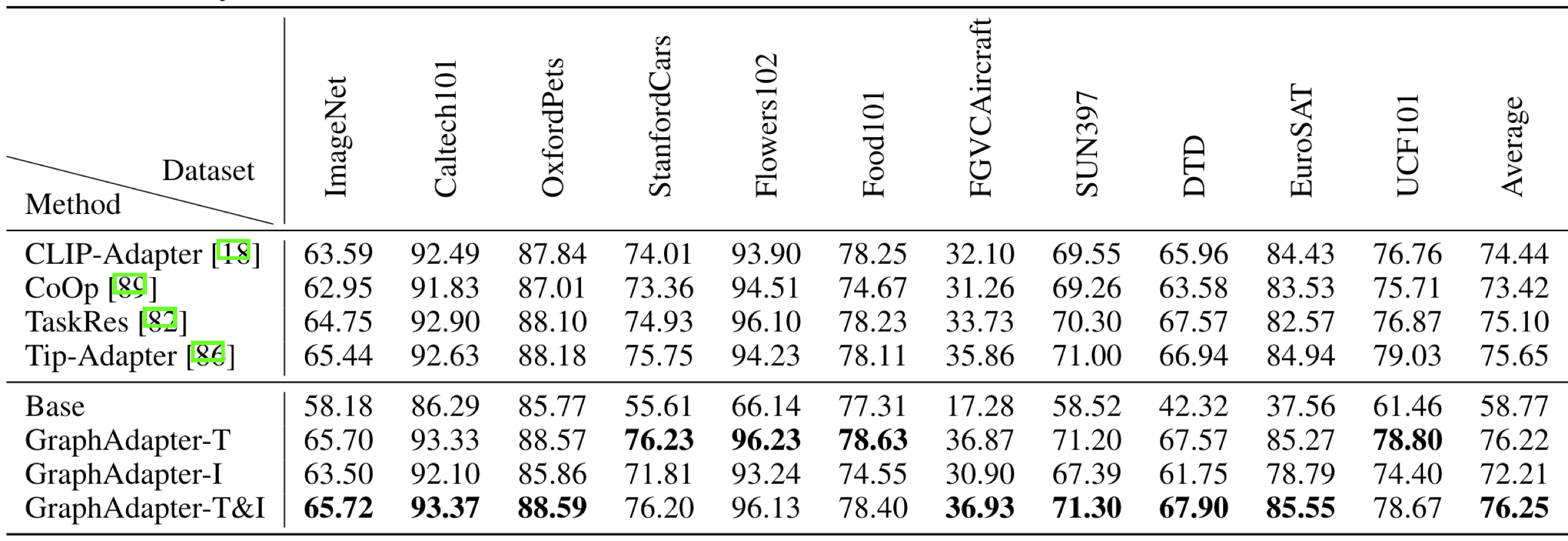
本文方法是通过GCN和KG增强预训练VLM的文本特征,因此消融实验尝试了增强图像、同时增强图像和文本。
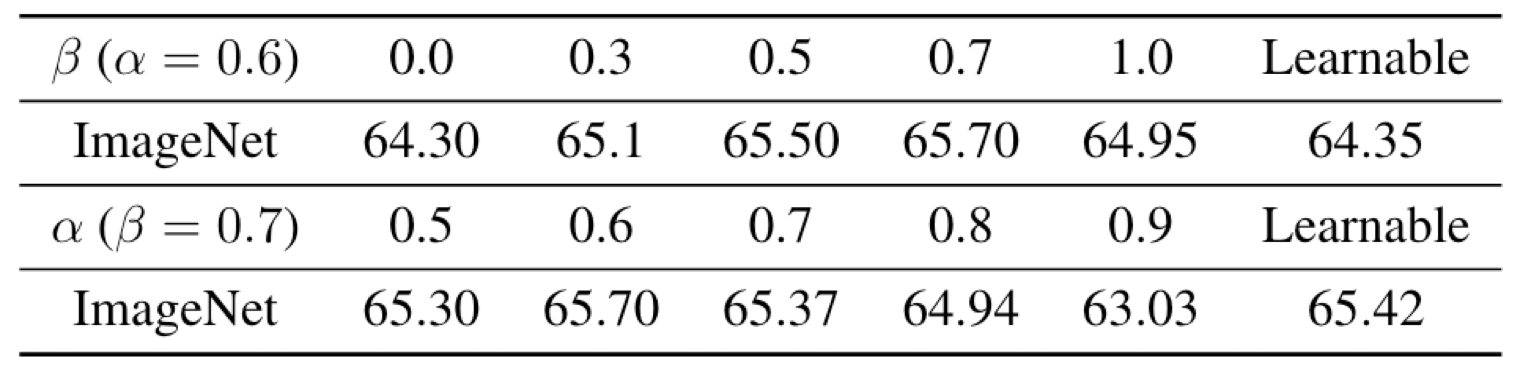
通过调节图像和文本的融合比例、增强特征和原始特征的融合比例,可以取得更好的效果;Learnable不如手工调整;
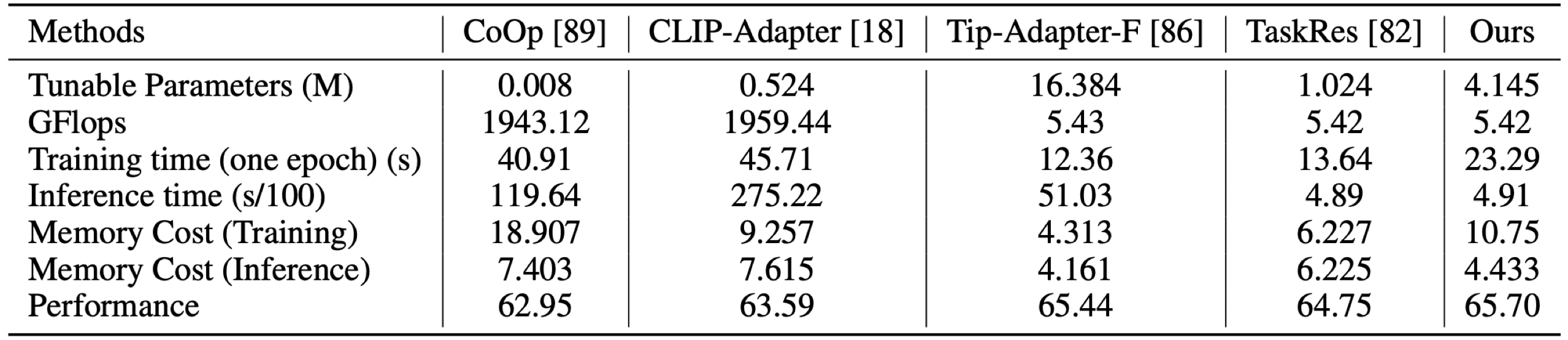
参数量和计算量处于合理水平
OpenReveiw主要质疑的是复杂度、规模扩展性和细粒度、开放世界问题。