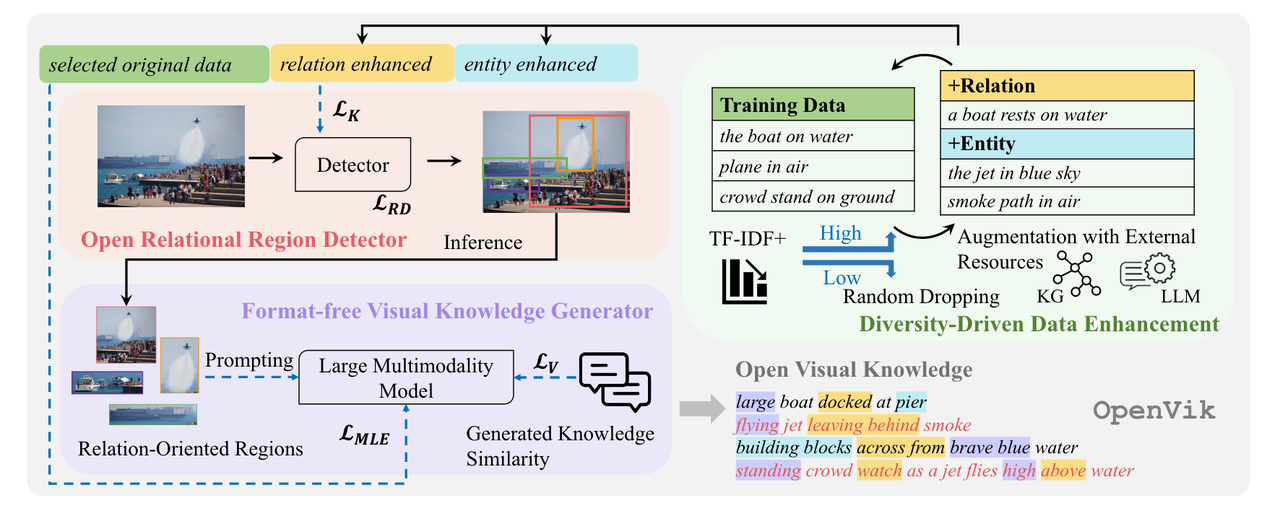
主任务:视觉知识抽取,分解为目标检测和文本生成
- 目标检测:Relation-centric(bbox改成subject和object联合区域,分类器目标改成关系类别
- 文本生成:改Loss,惩罚相似的生成
- 数据增强:使用KG、LLM扩充知识(从常识库中补充更多的关系,将主语替换为同义词);丢弃频繁知识(魔改TF-IDF);
并不是凭空抽取知识,训练依赖细粒度的标注(BBox,知识),数据集Visual Geonome
下游任务:文本检索图像,图像识别文本,VQA
模型:检测:ResNet+FPN,多模态生成:VIT-B-16+BLIP/CLIP(依赖大规模预训练)