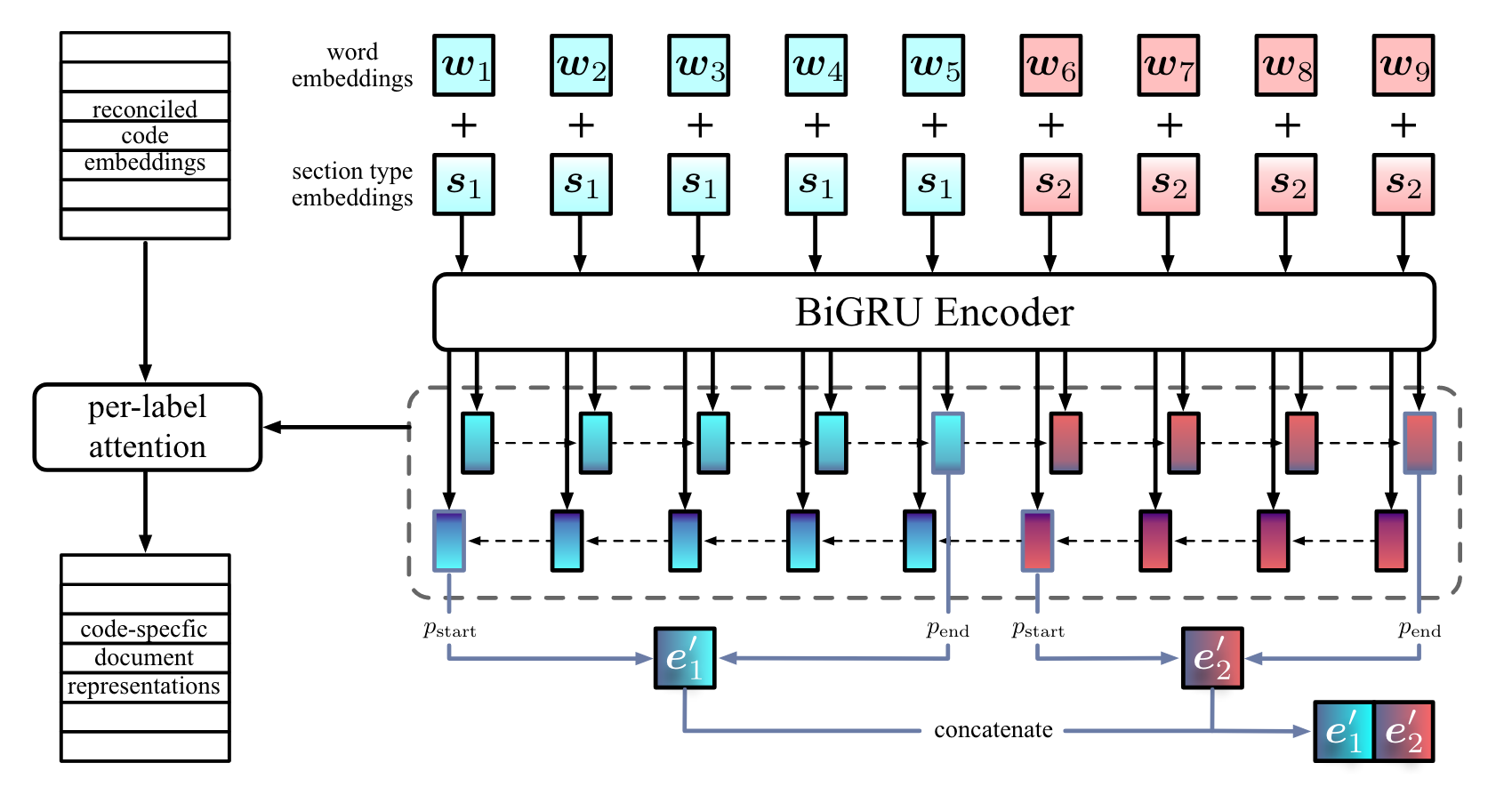
- Backbone:biLSTM
- Discourse Structure: 给不同的篇章加embedding,来帮助模型学习篇章结构
- 加了embedding容易过拟合,所以加了个0.5的dropout
- Reconciled Code Embedding: 为了解决ICD Code和病历文本交互时的异质性
- 从ICD Code和病历文本中学习向量各个维度的缩放比例、归纳偏置
- 同时,增加罕见病的注意力学习权重,以缓解类别不平衡
- 行云流水的魔改多尺度attention,配合了一些公式
- 可视化注意力得分高的区域,来展示模型的感兴趣部分
- 计算量随类别数增加(N^2),因此无法处理超大类别
details #
Adam学习率1e-5, Batch Size12, 正则化系数1e-4
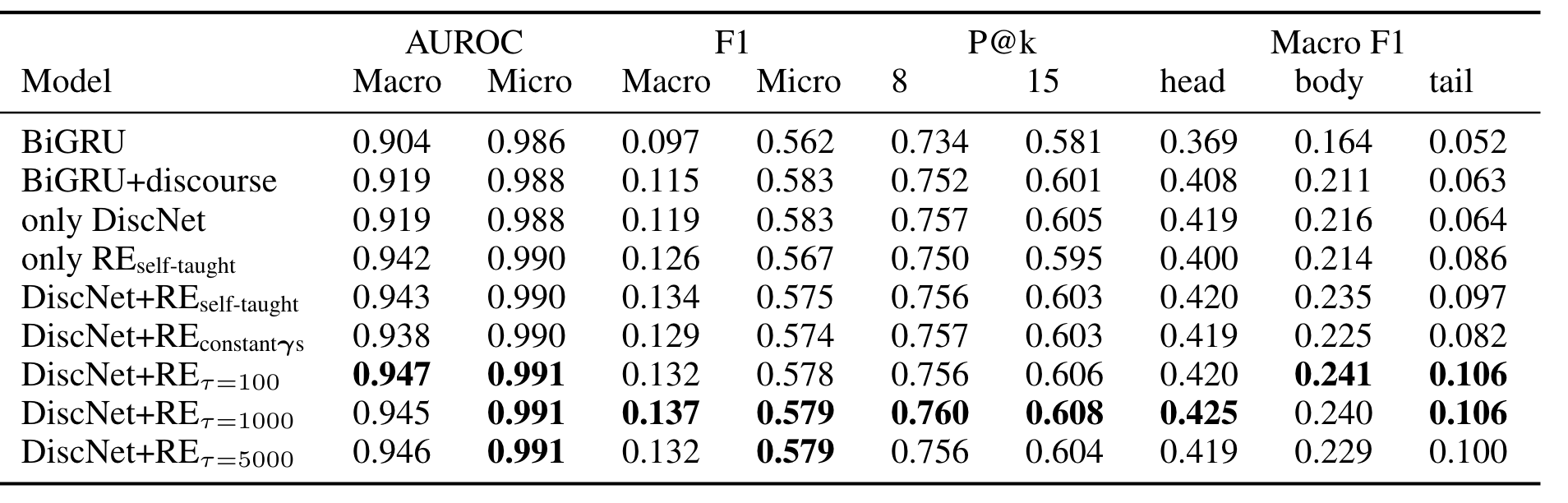
消融实验
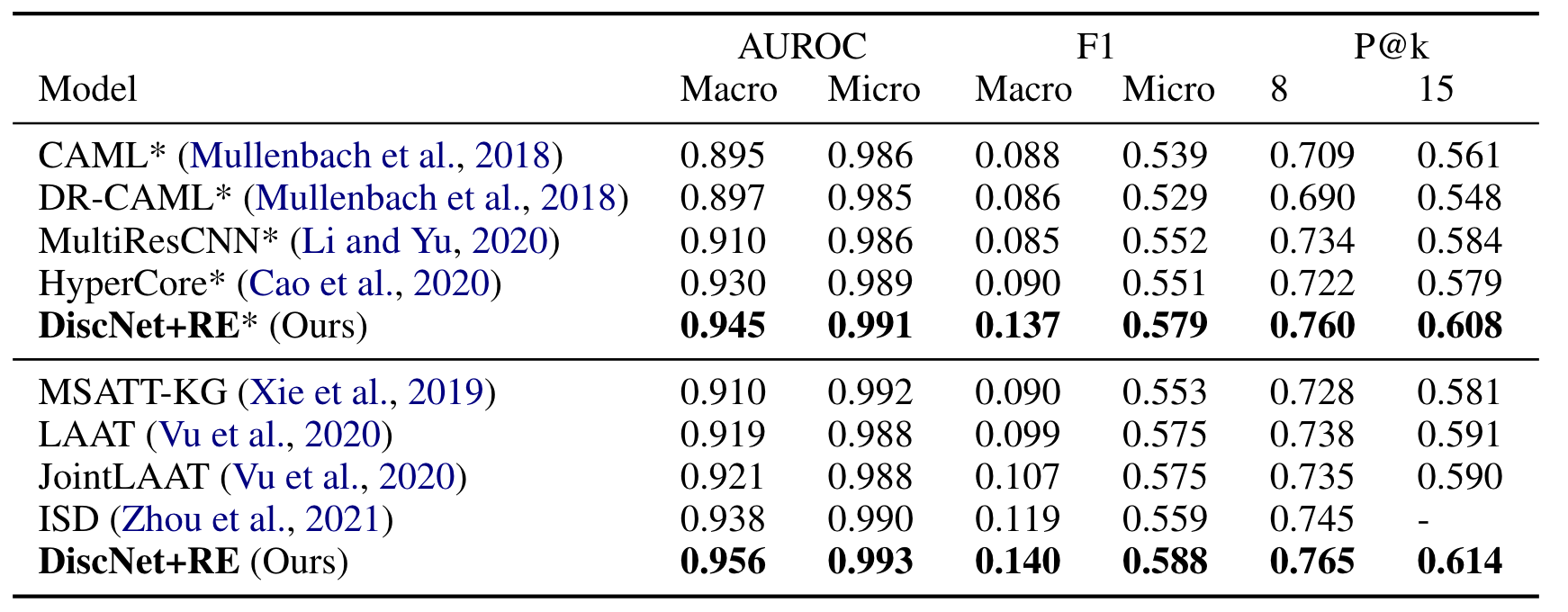
对比实验
Visualization #
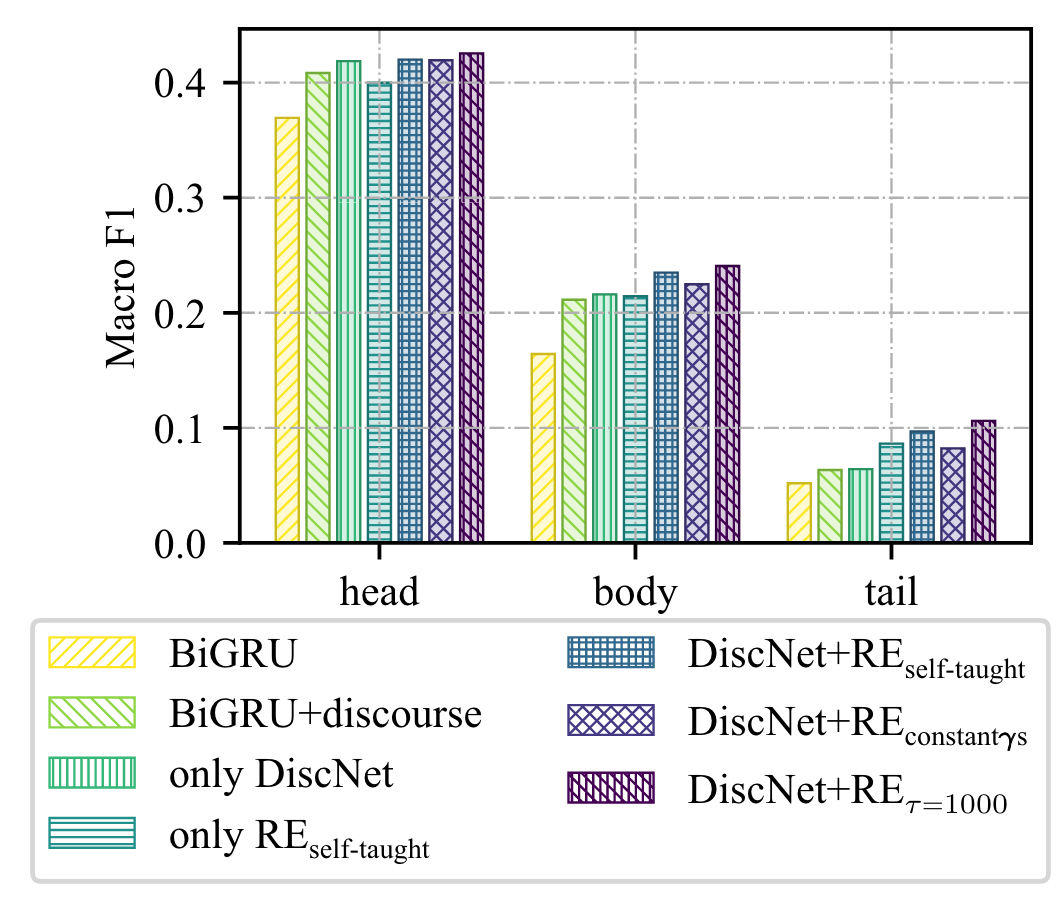
把测试集的标签按照样本频次划分成了head set(1446,f>50), body set(1779, 5<f<50), tail set(860, <5)
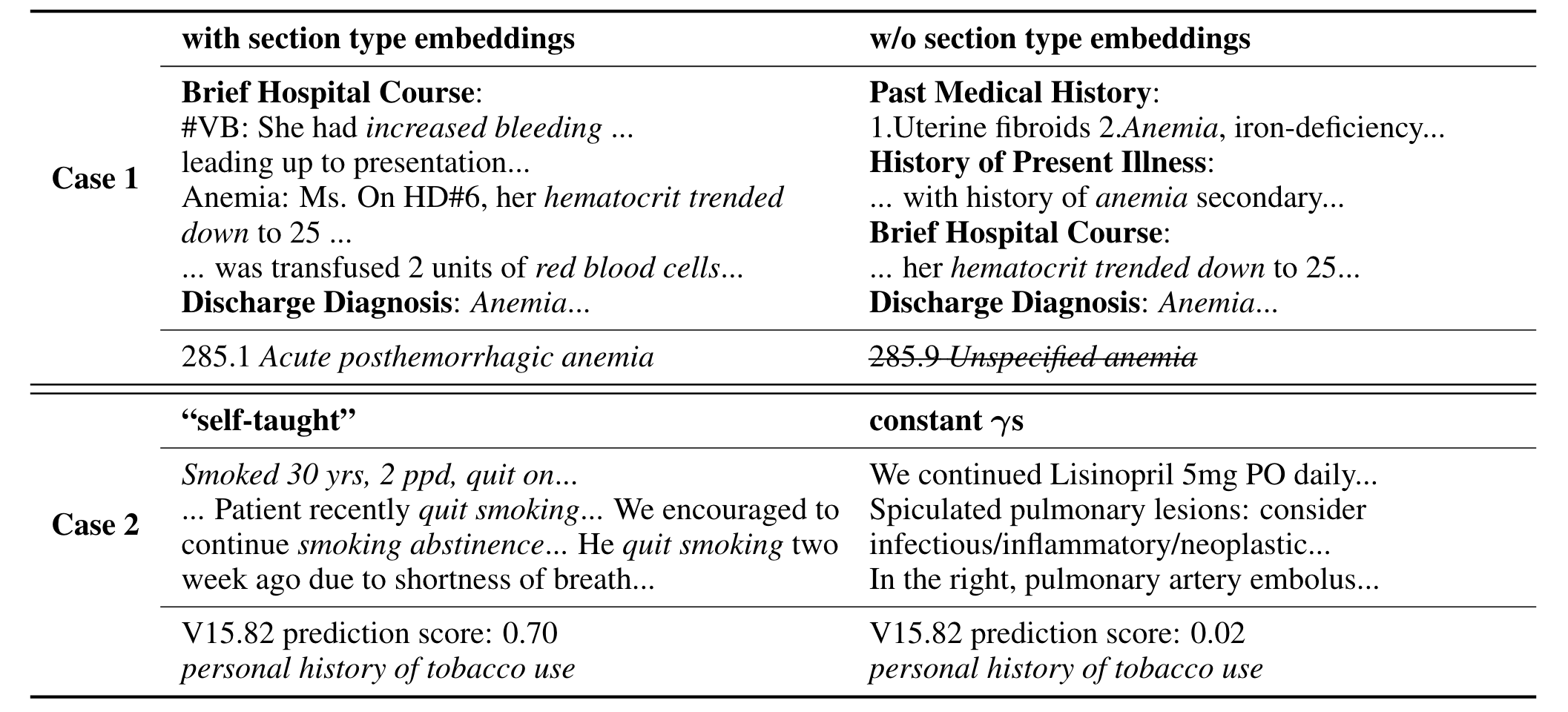
凸出了注意力得分高的区域,以展示模型的感兴趣部分
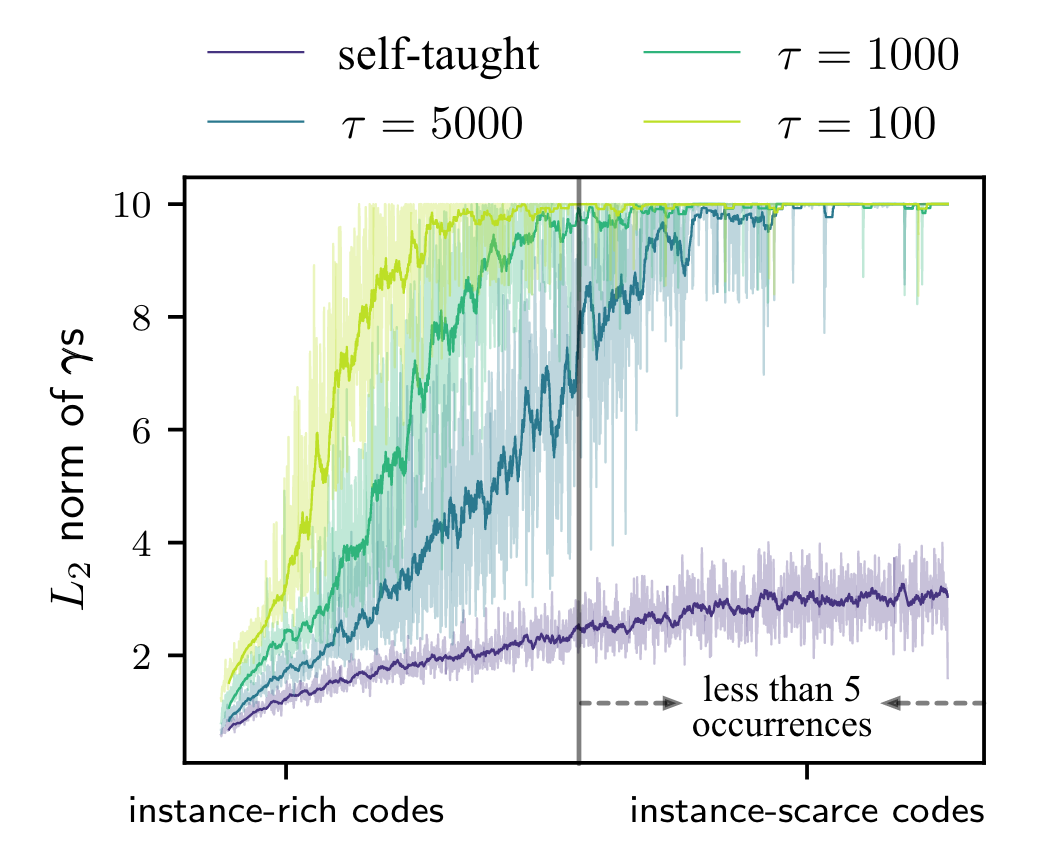
可视化了各个类别的注意力二范数,$\tau$是正则化的缩放比例