用统一的框架实现三个KG任务
- Multimodal Link Prediction
- Multimodal Relation extraction (MRE)
- MNER is the task of extracting named entities from text sequences and corresponding images (MNER)
框架 #
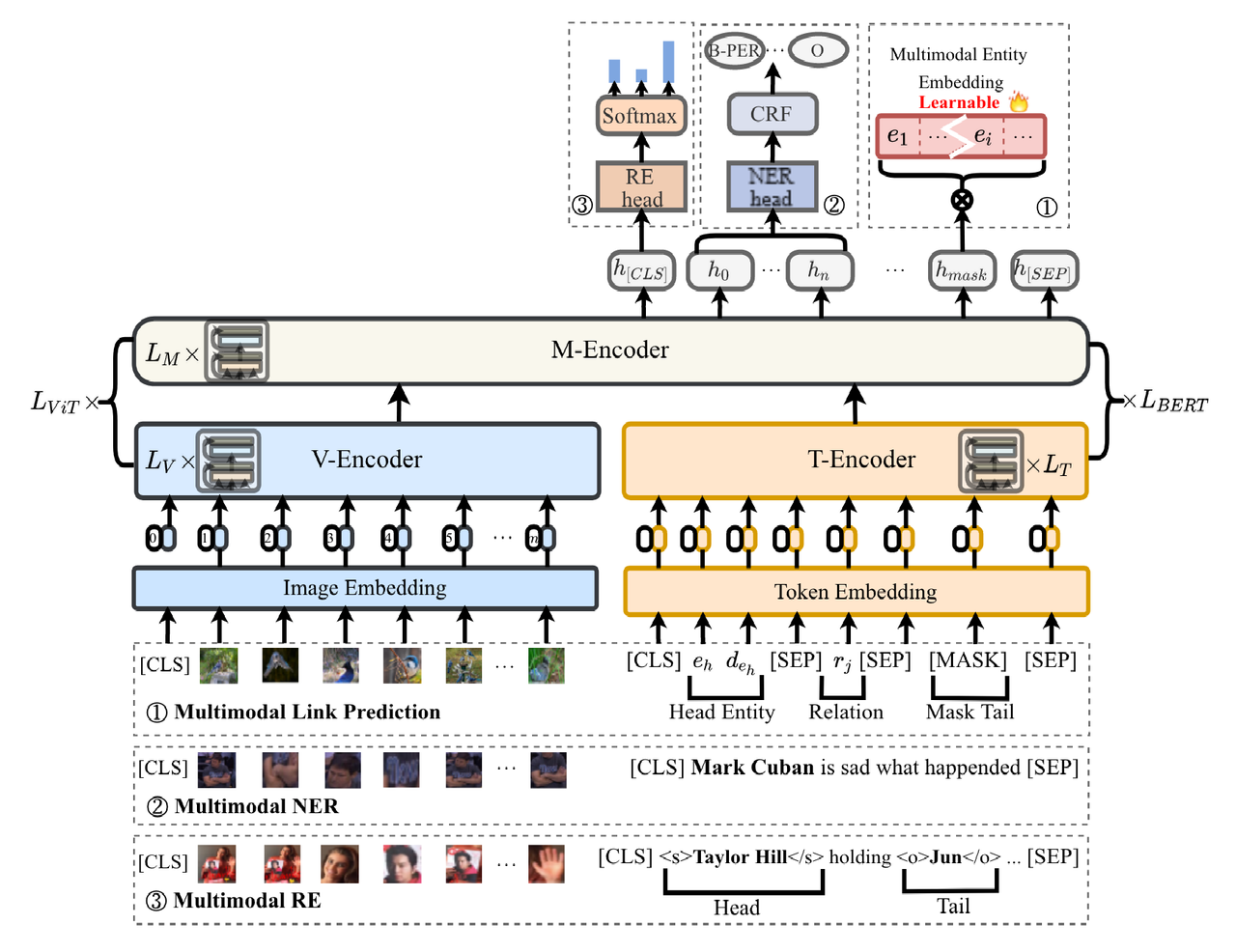
RE:对CLS token进行预测
NER:对每个词向量进行预测
链路预测:对mask token进行预测
模块 #
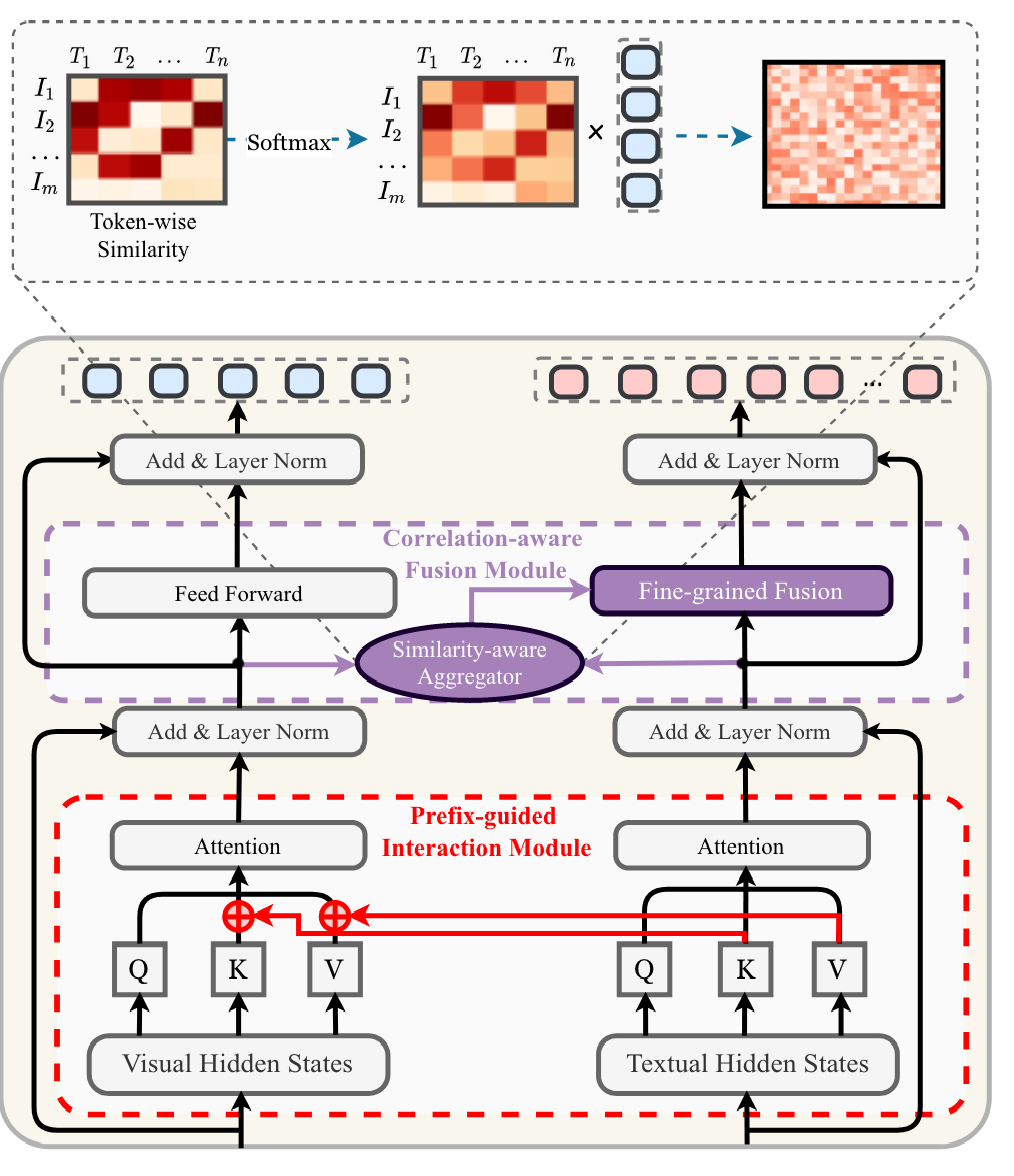
视觉:直接混合attention
文本:先self-attention再cross-attention
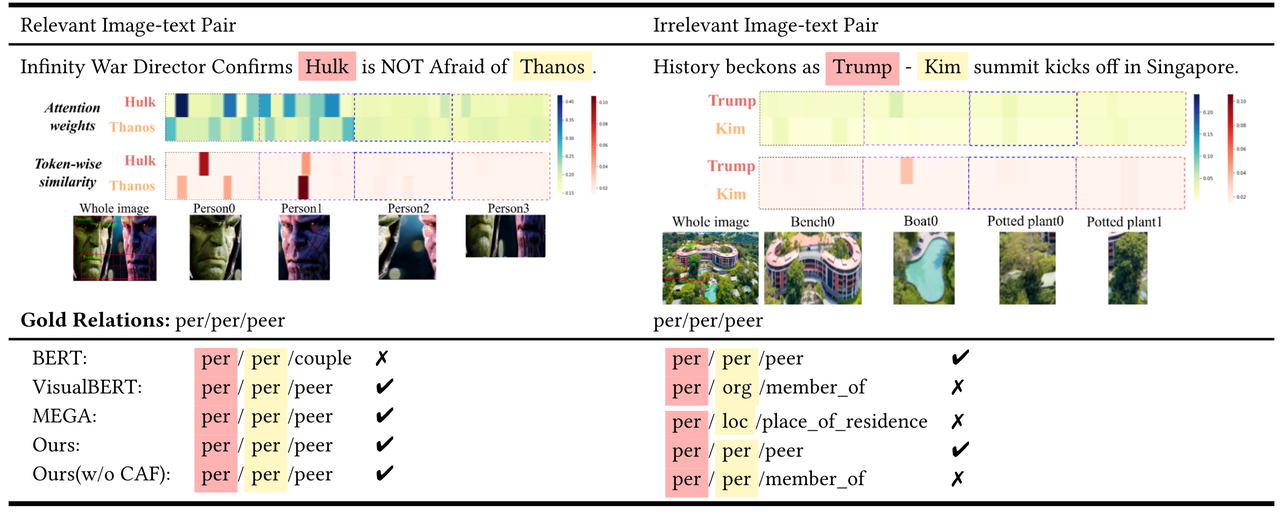
效果图 #