Arcitecture #
所有类型的神经网络都可以看成是线性变换+交互。线性变换是不变的,即对每一个像素/token/节点的特征向量进行相同的Linear+Activation;交互则取决于具体的任务:CNN的交互是相邻的像素点加权平均,RNN的交互是下一个token依赖上一个token,Transformer的交互是token与token之间的注意力加权平均,GNN的交互是一阶邻域内节点的加权平均。大部分模型结构层面的优化也是根据任务场景来设计新的交互方式。
CNN #
| Series | Model | Time Consumption | ||
|---|---|---|---|---|
| UNet | UNet | 2014 | 跳跃连接,精细分割 | |
| RCNN | RCNN | 2013 | 用CNN做Dectection,再用CNN做Classification | 40-50s |
| Fast-RCNN | 2015 | 使用同一个CNN计算bounding box和Label | 2s | |
| Faster-RCNN | 2015 | 去除了Selective Search | 0.2s | |
| Mask-RCNN | 支持Instance Segmentation | |||
| YOLO | Yolo v1 | 2015 | 用回归问题统一了Bounding Box的坐标预测和类别预测 | |
| Yolo v2 | 2016 | 支持不同输入尺寸 | ||
| Yolo v3 | 2018 | 支持多标签;引入多尺度; | ||
| Yolo v4, v5, v6 | 2020 | |||
| 2021 | ||||
| Yolo v6, v7 | 2022 | |||
| Yolo v8 | 2023 |
RNN #
感觉已经G了,不想写了,随便写点吧
| Model | ||
|---|---|---|
| RNN | t时刻的输出与t时刻的输入和t-1时刻的隐状态有关 | |
| LSTM | 设置遗忘门、输入门和输出门,输出是记忆和输入的加权和,以达到选择性遗忘和选择性输入的目的。 | |
| Mamba | 一文通透想颠覆Transformer的Mamba:从SSM、HiPPO、S4到Mamba |
Transformer #
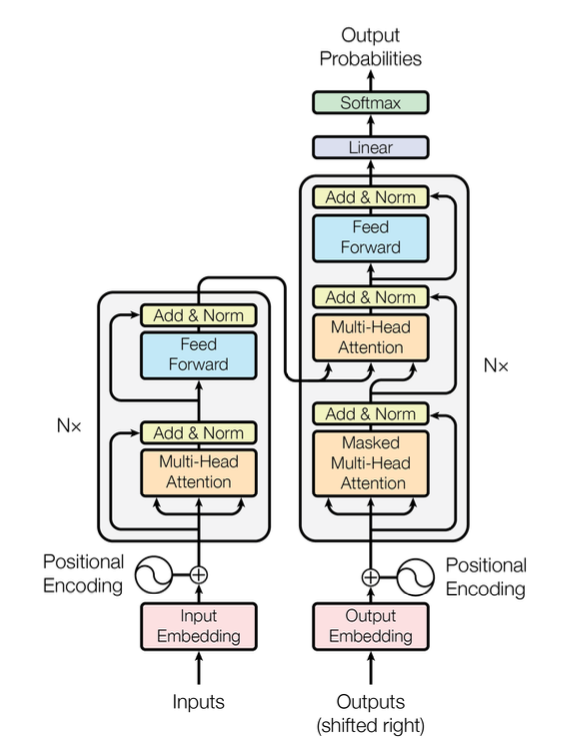
注意力机制:计算每个向量(Q)与其他向量(K, V)的相关性,用加权和取代原来的向量
多头:将c维向量拆成n个c/n维向量,分别使用注意力机制,然后再拼接回
| 多头注意力的使用方式 | 并行计算 | ||
|---|---|---|---|
| 自注意力 | Encoder | 第n个token是Q,当前Encoder层输入的所有token是K和V | 完全并行 |
| Decoder | 第n个token是Q,当前Decoder层输出的前n-1个token是K和V | 高度并行(Teacher Forcing) | |
| 交叉注意力 | Decoder | 第n个token是Q,最后一层Encoder输出的所有token是K和V | 高度并行(Teacher Forcing) |
| Series | Model | ||
|---|---|---|---|
| BERT | Roberta | 字节对编码(BPE);动态掩码;去除NSP;大bs和大lr;10倍规模的数据集; | |
| Albert | Embedding低秩矩阵分解;NSP改成SOP;跨层attention参数共享; | ||
| ERNIE (THU) | 设计Aggregator来使文本和实体进行充分交互;使文本在映射后可以预测实体; | ||
| ERNIE1.0 (Baidu) | 在MLM阶段额外进行phrase-level和entity-level的mask | ||
| ERNIE2.0 (Baidu) | 持续多任务学习,渐进地增加更复杂的任务 | ||
| GPT | GPT-2 | Pretraining+Zero-Shot | 在9个任务上超过有监督SOTA;在摘要、翻译、问答等任务上不如无监督模型 |
| GPT-3 | Pretraining+Few-Shot | 超过了有监督BERT,尚未超过有监督SOTA | |
| GPT3.5:InsturctGPT | GPT3+SFT+RM+PPO | ||
| VIT | 将图片拆成patch,每个patch通过reshape和MLP转化为词向量,送入Tansformer的encoder | ||
| SwinTransformer | |||
| UNETR | Transformer Encoder + UNet Decoder | ||
| SwinUnet |
GNN #
在神经网络兴起之前,主流方法是通过构造合理的度量函数来优化每个实体的表示
| KG2E | 度量函数 | 建模关系 |
|---|---|---|
| TransE | 平移 | Inversion; Composition |
| DisMult | 双线性 | Symmetry; |
| CompIEx | 复空间内积/共轭内积 | Symmerty; Antisymmerty |
| RotateE | 复空间旋转 | Inversion; Compostition; Symmertry; |
随着神经网络的发展,GNN被提出,通过建模邻域节点的特征,来获取更好的中心节点表示;GNN的层数一般取2或3
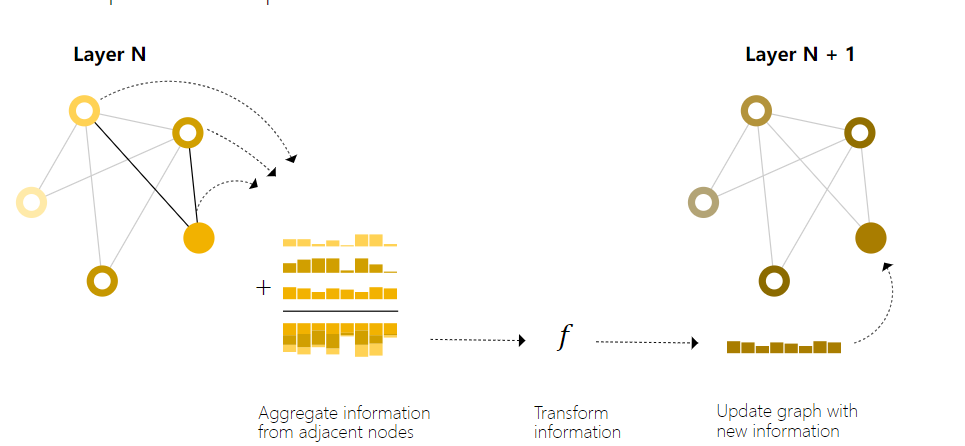
| GNN | 聚合方式 | |
|---|---|---|
| GCN | 邻域内平均 | |
| GAT | 邻域注意力加权 | |
| GraphSAGE | 邻域,区分自身和邻居 |
通常情况下,每次前向传播是将采样的子图作为一个Batch,以当前子图上所有含有标签的节点/边作为监督信号计算Loss并进行反向传播。
Application #
AlphaGo #
AlphaGo 的训练分为几个阶段:
- 策略网络:Supervised Learning
- 数据来源:从人类棋谱中收集大量数据。
- 目标:通过神经网络拟合人类的落子策略,训练初始的策略网络,使其能够预测人类棋手的走法。
- 方法:利用交叉熵损失函数优化策略网络。
- 策略网络:Reinforcement Learning
- 数据来源:AlphaGo 自我对弈产生的新棋谱。
- 目标:在与自身对弈的过程中改进策略网络,使其超越人类棋谱中的策略。
- 方法:基于策略梯度方法优化网络,最大化自我对弈的胜率。
- 价值网络:Reinforcement Learning
- 数据来源:大量终局数据,标注每个局面的实际胜负结果。
- 目标:通过监督学习训练价值网络,使其能评估局面的胜率。
- 蒙特卡洛树搜索:MCTS
- AlphaGo 将策略网络和价值网络结合到蒙特卡洛树搜索中进行优化。
- 策略网络指导扩展和模拟,价值网络评估局面,提升搜索的效率和精度。
VAE #
变分:用人为构造的分布近似无法准确获知的分布;例如在贝叶斯公式中丢弃分母就是一种变分
熵:信息量的期望;概率越小熵越大;独立事件的熵具有可加性
KL散度:真实分布和估计分布的交叉熵-真实分布的熵;两个分布差别越大,KL散度越大;不是对称度量;
推导:为了用Encoder拟合出$P(z|x)$的分布,需要最小化两者的KL散度,然后通过推导(X的分布于Z的分布无关,联合概率和条件概率,等等)得出只需最大化ELBO,进一步化简ELBO的相反数,即可得到损失函数
损失函数:Z条件下X的分布的对数似然(正态分布下是X和预测结果的插值)+ X条件下Z的分布和正态分布的KL散度(有解析解)
重参数化:将采样转化为标准正态随机变量和X条件下Z分布的参数的线性运算
DDPM #
前向(加噪):给定某个图像,视为从latent space中的一次采样,可以计算出从噪声扩散成图像的过程中的每一步图像,常见的步数有10步、20步、100步
逆向(去噪/采样):训练神经网络,可以从每个时刻扩散到下一时刻,并基于最新时刻的采样点,,扩散成想要的图像
应用
-
Restoration:根据加噪类型,添加合理的逆变换,以最大程度保留原图特征,然后基于此训练扩散模型
-
Generation:施加不同的噪声,产生多样化的结果
Metrics #
Label Ranking Average Precision
在Multi Label问题中,对于每个Positive Label,用按照logits从高到底排序查找该Label,用过程中所有的Positive Label除以该过程中涉及的Label个数,即为该Label的LRP。 $$ MAP=\frac{1}{N_Y}\sum_{y\in Y}{Precision@Rank(y)} $$
Learning #
Contrastive Learning #
InstDisc:提出了个体判别的代理任务,核心思想是每张图片都是一个类 #
batch_size=256, 256个正样本,4096个负样本 Backbone是ResNet50,2048降维到128 200个epoch,温度0.07,学习率1e-2
数据结构:memory bank
InvaSpread:端到端,SimCLR前身 #
端到端,正负样本来自同一个mini batch,正样本是任一图片及其变换,负样本是其他图片及其变换
因为字典不够大(batchsize只有256),数据增广不够,没有加MLP,因此效果不好
MoCo:提出了“字典查找”的概念,认为对比学习本质上是在构建一个大字典 #
用队列取代memory bank
使用动量编码来解决大字典内key的不一致,由于key的编码器更新缓慢,因此可以认为一致
损失函数:infoNCE
普适性强,Q和K的编码器可以不同,输入可以是任意模态
simCLR:成功实现了端到端的对比学习 #
只有一个编码器
- 更多的数据增强:对比学习非常依赖数据增强
- 对比学习时增加了一个MLP层(迁移到下游任务时去除)
- 更大的batchsize:从而实现端到端训练
MoCov2 #
MoCo+数据增强+MLP+cos schedule
batch=256时,效果远优于sim CLR
simCLRv2 #
模型更大
MLP:fn-ReLu-fn
动量编码器
Meta Learning #
参考:Meta-Learning in Neural Networks*: A Survey(2020)
Meta-learning经常被理解为learn to learn,可以分为两个阶段:内循环和外循环。
内循环阶段,模型利用训练样本拟合某个特定任务;在外循环阶段,对外循环的某个目标函数进行优化。
内循环和外循环迭代交替进行。
MAML: Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks(2017) #
与传统机器学习的区别
- 传统机器学习:训练集和测试集是同一个task,在训练集样本上训练模型,希望模型在测试集样本上表现好
- MAML:task不同,在训练集可见的task上训练模型,希望在未见过的task上效果好
- 利用训练集的task学习一个初始化参数,使这个参数在未见过的任务上finetune几轮,就能达到较好的效果
两个阶段:meta-train(内循环+外循环迭代更新,support set & query set)、meta-test(在具体任务上finetune)
Reinforcement Learning #
| 监督学习(Supervised Learning) | 强化学习(Reinforcement Learning) | |
|---|---|---|
| 数据形式 | 独立同分布(i.i.d)的样本-标签对 (x,y)(x,y) | 时序相关的状态-动作-奖励序列 (s,a,r)(s,a,r) |
| 反馈类型 | 显式标签(正确答案) | 延迟且稀疏的奖励信号(如游戏得分) |
| 学习目标 | 最小化预测误差(如交叉熵损失) | 最大化长期累积奖励(通过策略优化) |
| 环境交互 | 无需与环境实时交互 | 需通过试错与环境动态交互 |
| 探索与利用 | 无需平衡探索与利用 | 需在探索新动作和利用已知高奖励动作间权衡 |
| 典型任务 | 图像分类、文本翻译 | 游戏控制、机器人导航 |